- システム全体で何が起こっているかを理解する
- ユーザーに影響を与える前に問題を特定します
- 遅いプロセスまたは失敗したプロセスを特定することでシステムのパフォーマンスを向上させます。
ダッシュボードビュー
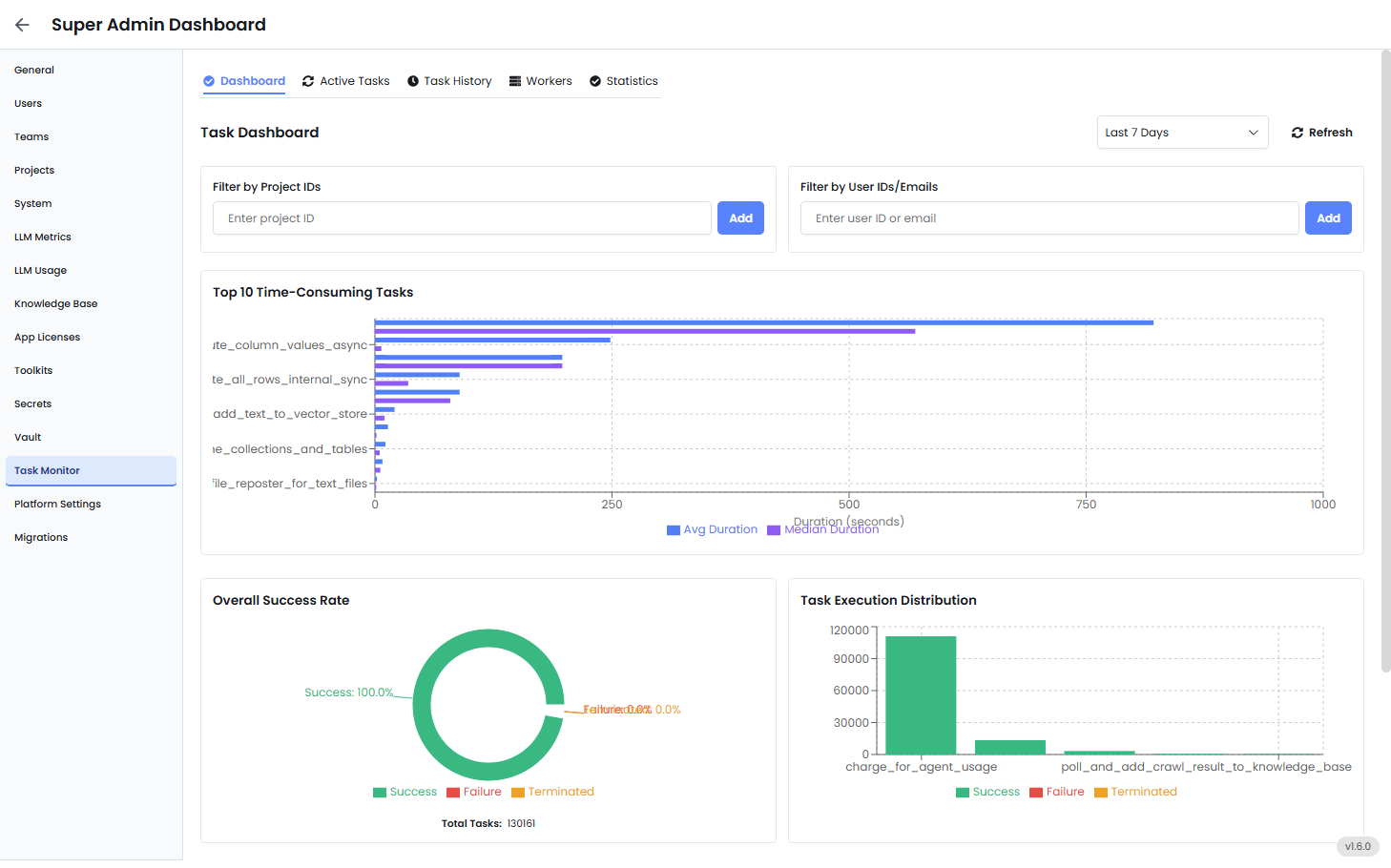
フィルター (トップパネル)
フィルターを使用して、以下に基づいて結果を取得します。- プロジェクト ID: タスク アクティビティを特定のチームまたはイニシアチブから分離します。
- ユーザー ID または電子メール: 特定のユーザーによって実行されたタスクを監査またはトラブルシューティングします。
- 日付範囲: デフォルトは過去 7 日間ですが、調整できます。
- 更新ボタン: タスク実行ログから最新のデータを取得します。
時間のかかるタスク トップ 10
この棒グラフは、システム レコードに基づいて、実行に最も時間がかかっているタスクをリストします。- 平均所要時間 (青色のバー): このタスクがすべての実行にかかる平均時間。
- 期間の中央値 (紫色のバー): 中央の値 — いくつかの遅いタスクが平均を歪めているかどうかを特定するのに役立ちます。
- どのタスクが最もリソースを消費しますか?
- 異常値はありますか (例: 1 つのタスクが通常時間の 3 倍に急増するなど)。
- 特定のロジックを最適化、再スケジュール、または分割する必要がありますか?
全体的な成功率 (ドーナツ グラフ)
このグラフは、タスクの結果という観点からシステムの健全性を示しています。- 成功 – タスクはエラーなしで完了しました。
- 失敗 – タスクでエラーが発生しました (API エラー、タイムアウト、不正なデータなど)。
- 終了 – タスクは完了前に、手動またはシステム制限によって強制的に停止されました。
タスク実行分散
このグラフは、各タスクが実行される頻度、およびタスクが成功または失敗する頻度を示します。 各タスクについて:- 緑色のバー = 成功した実行
- 赤いバー = 失敗
- オレンジ色のバー = 終了した実行
- 最も頻繁に使用されるタスクはどれですか?
- 頻繁に実行されるが頻繁に失敗するタスクはありますか?
- 度重なる失敗により、重要なワークフローが中断されていませんか?
タスク期間の範囲
このグラフは、各タスクにかかる時間を時間の経過とともに分析します。タスクごとに、次のようにプロットされます。- 平均期間
- 期間中央値
- 最大持続時間
- 最小継続時間
- バックエンドの速度低下
- 入力異常
- サードパーティ API からのレート制限
管理者が定期的に行うべきこと
| Task | Why It’s Important PLACEHOLDER_1 Check the top time-consuming tasks weekly | Identify candidates for optimization or review PLACEHOLDER_2 Investigate spikes in failures or terminations | Prevent cascading failures in automated workflows PLACEHOLDER_3 Monitor most frequent tasks | See what’s driving system load and how to prioritize scaling PLACEHOLDER_4 Filter by project/team | Hold teams accountable for clean and efficient automations PLACEHOLDER_5 Review success rate over time | Track improvement or degradation in platform reliability |管理者の使用例の例
チームが「今週はドキュメントの取り込みが遅い」と報告したとします。- [タスク モニター] タブを開きます。
- そのチームのプロジェクト ID でフィルターします。
- 「最も時間のかかるタスク」を見て、遅いワークフローを見つけます。
- 「タスク期間の範囲」を使用してスパイクを特定します。
- 失敗が関係する場合は、「タスク実行分布」と「全体の成功率」に進みます。