- 概要
- API
スマートテーブルは、ナレッジベース(KB)内の構造化データ管理機能で、テーブル形式でデータを保存・整理・抽出できます。一般的なスプレッドシートとは異なり、スマートテーブルはAI機能と統合されており、ドキュメントからの自動データ抽出、異なるデータセット(コレクション)間のリレーションシップマッピング、AIエージェントを通じた直接クエリが可能です。主な機能:
エージェントはスマートテーブルに対してクエリを実行し、自然言語で回答を返します。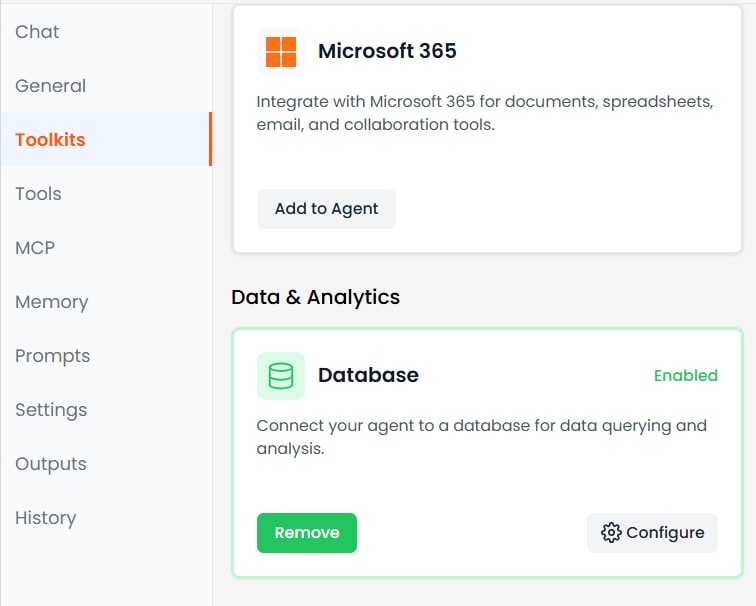
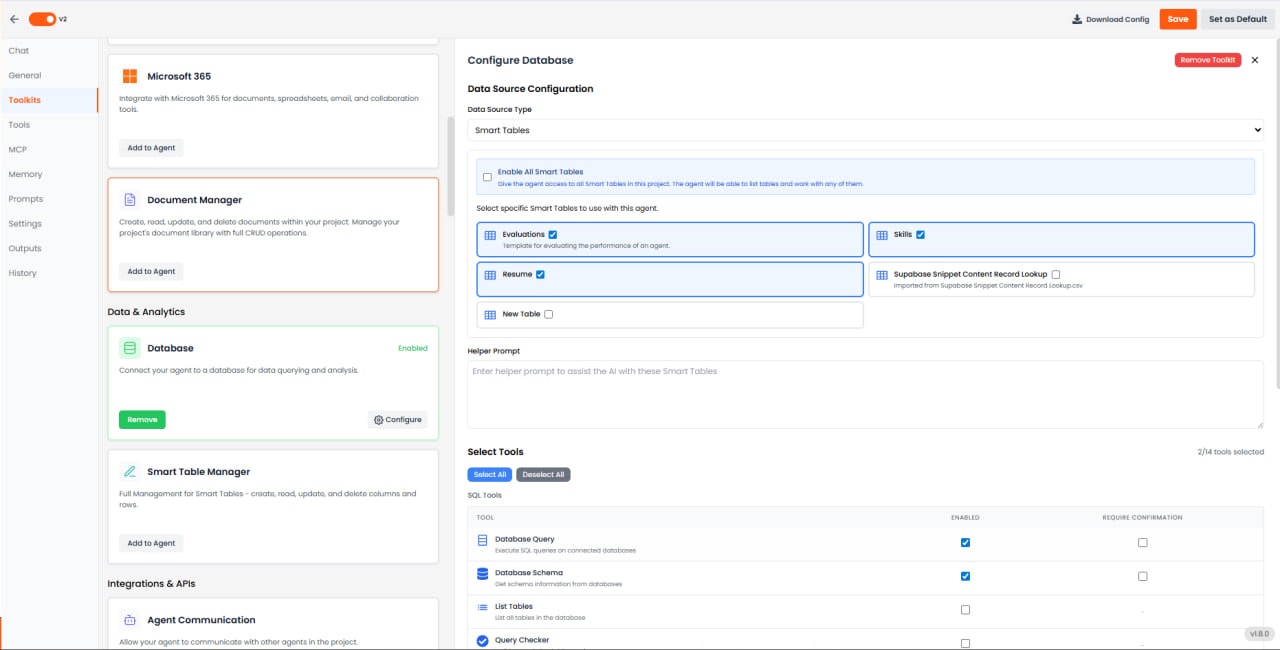
- 構造化スキーマの定義 — カラム、データ型、フォーマット
- アップロードされたファイルからの自動データ抽出(例:履歴書、請求書)
- 内蔵ダッシュボードによるデータの可視化
- エージェントを使用した自然言語でのテーブルデータクエリ
スマートテーブルへのアクセス
スマートテーブルは、アプリケーションの**ナレッジベース(KB)**セクションからアクセスできます。作成後、KBデータセクションに移動してスマートテーブルを表示・管理できます。すべてのテーブルが一覧表示され、表示や編集のために開くことができます。スマートテーブルの作成
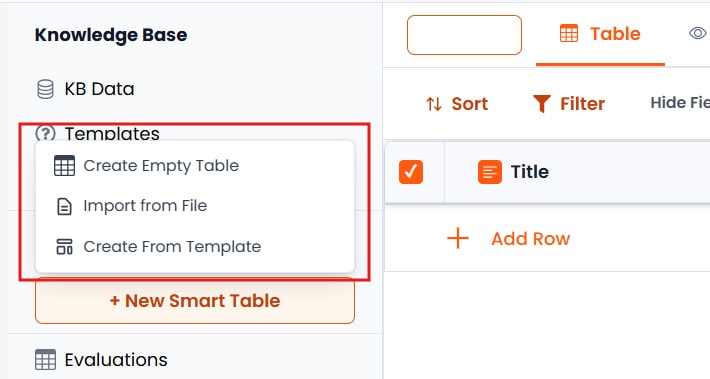
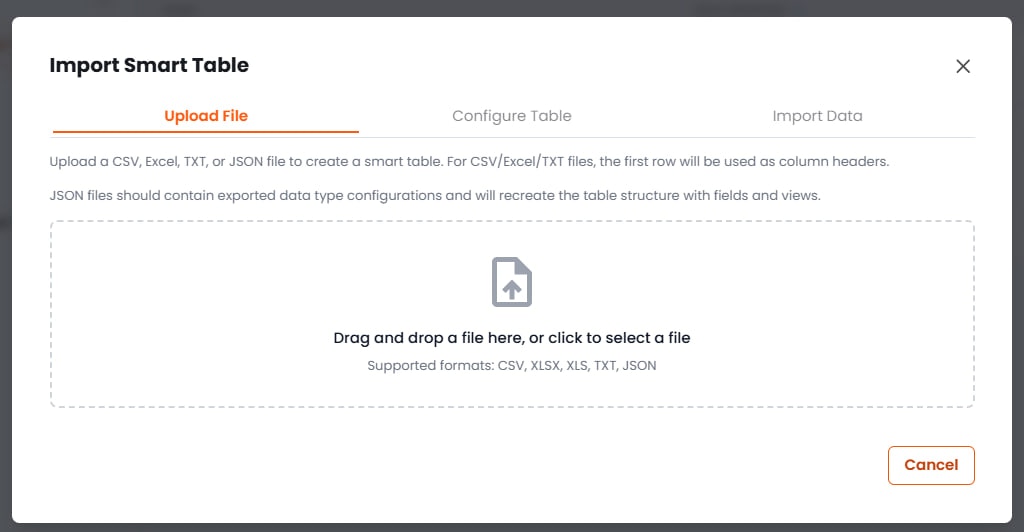
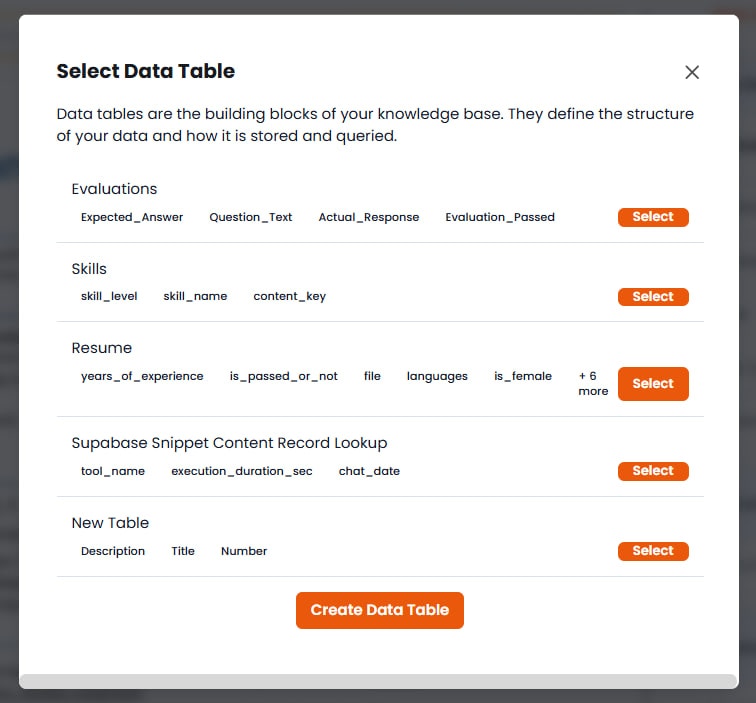
ナレッジベース内でスマートテーブルを作成するには、主に3つの方法があります。KBインターフェースの作成メニューをクリックしてこれらのオプションにアクセスします。方法A:空のスマートテーブルを作成
このオプションは、デフォルトのシステムカラム(タイトル、説明、番号)を持つ空のテーブルを作成します。サイドバーの構成パネルが自動的に開き、カスタムスキーマをゼロから定義できます。これらのデフォルトフィールドを維持したり、変更したり、削除して独自の構造を作成したりできます。方法B:テンプレートから作成
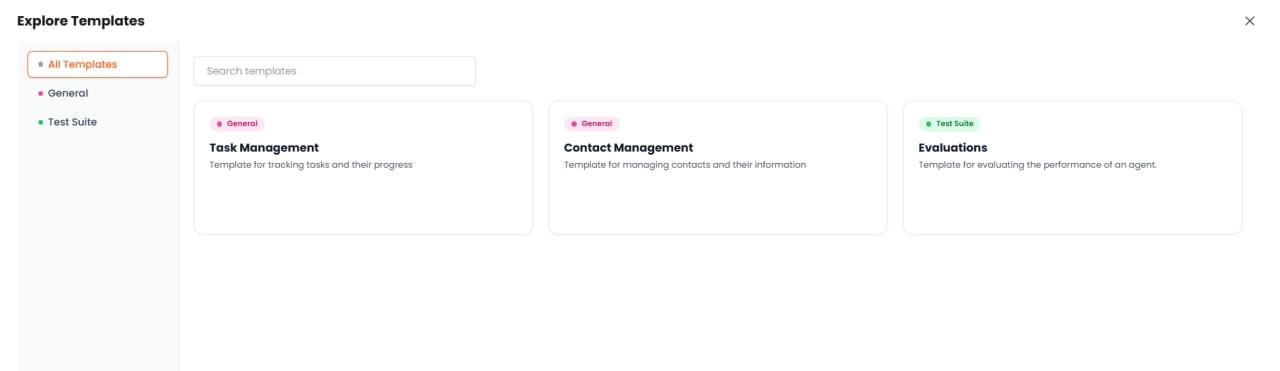
事前定義されたテンプレートを選択して、一般的なユースケース向けにテーブルを迅速にセットアップできます。さまざまなシナリオ向けに複数のテンプレートが用意されています。例えば、評価テンプレートはエージェントの応答をテストするために設計された事前定義カラムセットをインポートします(質問テキスト、期待される回答、実際の応答)。方法C:ファイルからインポート
CSVファイルをアップロードして、スマートテーブルを自動的に作成できます。システムはCSVヘッダーを解析してカラムを作成し、行をデータエントリとしてインポートします。カラムの種類と設定
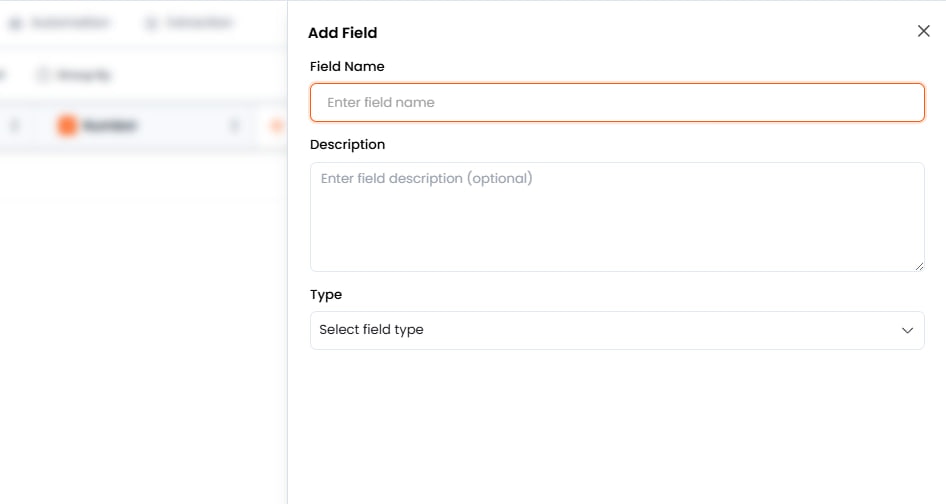
スマートテーブルを設定する際、各カラムには正確なデータ保存と抽出のために特定の定義が必要です。カラムは名前、型、フォーマット、ツールソースで構成されます。各カラムに明確な説明を提供することが非常に重要です。この説明は、大規模言語モデル(LLM)に対して、そのフィールドからどの特定情報を抽出または生成すべきかを指示します。
カラムの設定
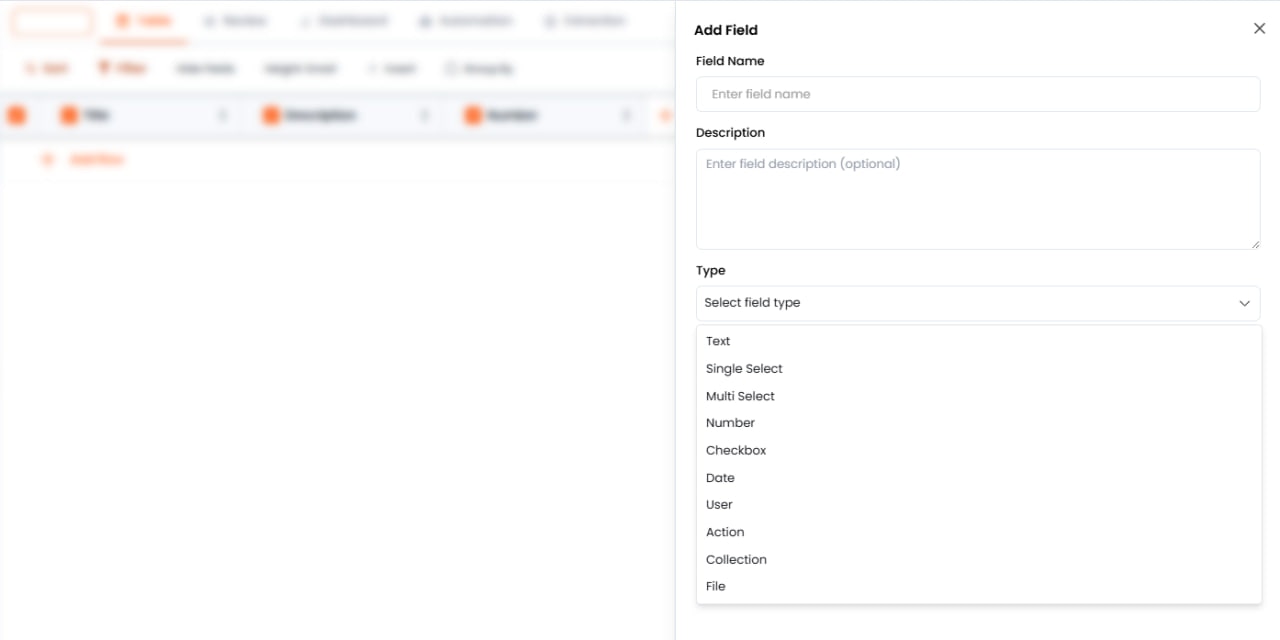
スマートテーブルの作成または編集時に、サイドバーパネルを使用して各カラムを設定します。フィールドのプロパティ(名前、型、フォーマット、ツール、説明)を設定した後、フィールドを保存をクリックして設定を適用します。カラム設定パネルでフィールド名をクリックし、変更を加えて再度保存することで、いつでも既存のフィールドを編集できます。フィールドの種類とフォーマット
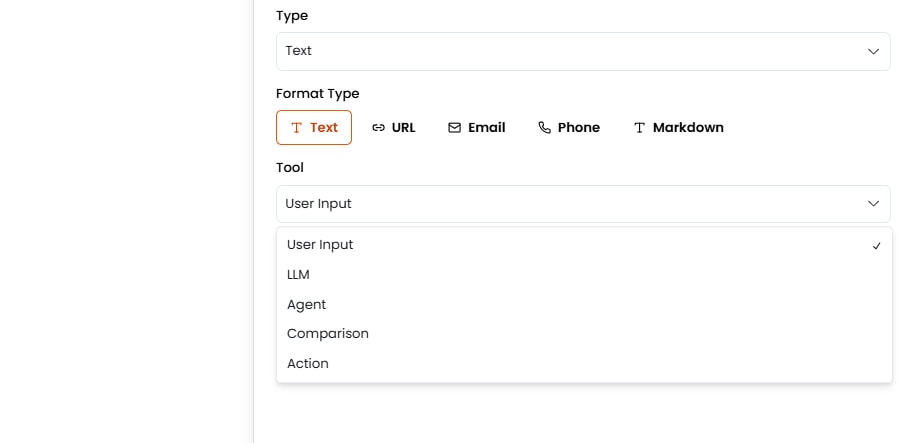
ツールソース
ツール設定は、データがセルにどのように入力されるかを定義します:- ユーザー入力 — データがユーザーによって手動で入力されるか、変更なしにファイルから直接抽出される
- LLM生成 — AIモデルがカラムの説明とコンテキストに基づいてコンテンツを生成する(例:履歴書の要約)
- エージェント生成 — エージェントがクエリを処理し、応答でこのフィールドを入力する
-
比較 — 2つのフィールドを比較し、一致するかどうかを判断するか、類似度スコアを計算する
データ抽出(ドキュメント処理)
スマートテーブルは、アップロードされたドキュメントからデータを抽出することで、行を自動的に埋めることができます。これは、履歴書やフォームなどの標準化されたドキュメントを処理する際に特に便利です。アップロードされた各ドキュメントはスマートテーブルに1行を作成しますが、複数のドキュメントをアップロードして処理することで、同じテーブルに複数の行を作成できます。ワークフロー:履歴書抽出の例
1
スキーマの定義
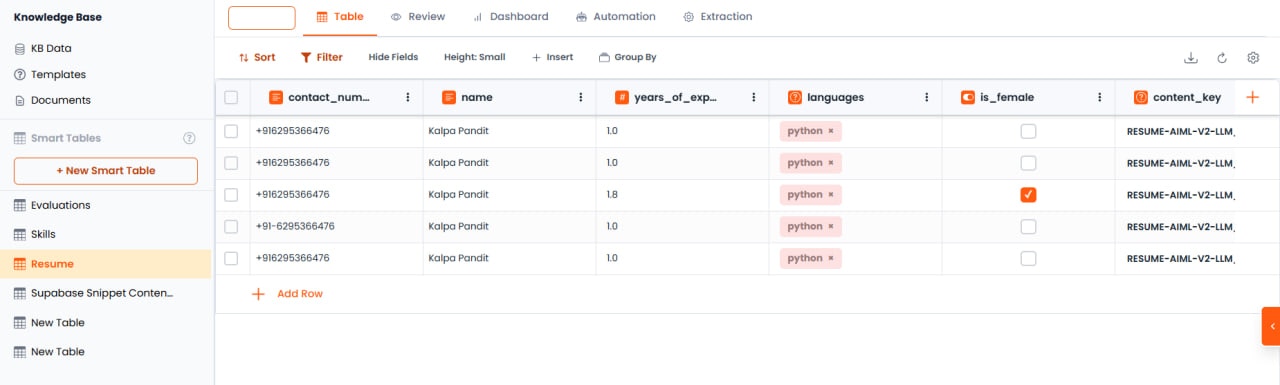
以下のカラムを持つ「履歴書」という名前のスマートテーブルを作成します:
- 名前(テキスト)
- 連絡先番号(テキスト — 電話番号フォーマット)
- 経験年数(数値 — 小数フォーマット)
- 言語(複数選択:Python、Java、HTML、CSS)
- 女性(チェックボックス)
- 履歴書ファイル(ファイル)
2
ドキュメントのアップロード
ナレッジベースに移動し、ファイル(例:PDFの履歴書)をアップロードします。
3
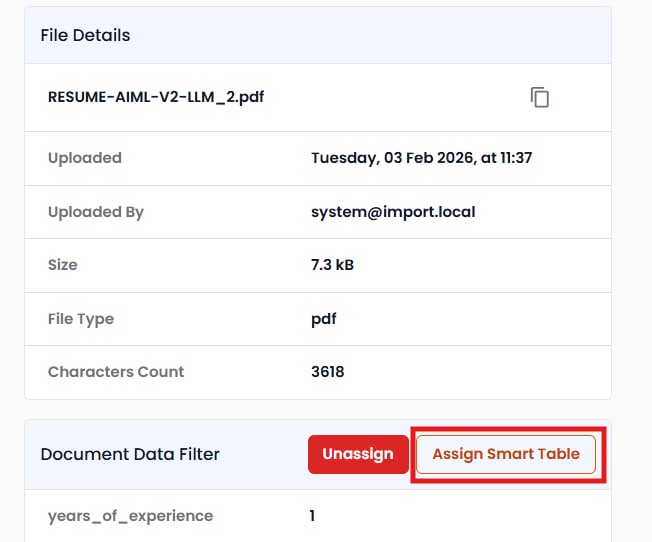
スマートテーブルの割り当て
アップロード時に「履歴書」スマートテーブルを選択します。
4
抽出
システムがドキュメントを処理し、定義されたカラムにコンテンツをマッピングします — 例えば、テキスト内の「3年」を見つけて経験年数を入力したり、連絡先番号の電話番号を抽出したりします。
5
結果の確認
スマートテーブルに移動して、抽出されたデータを含む新しい行を表示します。
コレクションとリレーションシップ
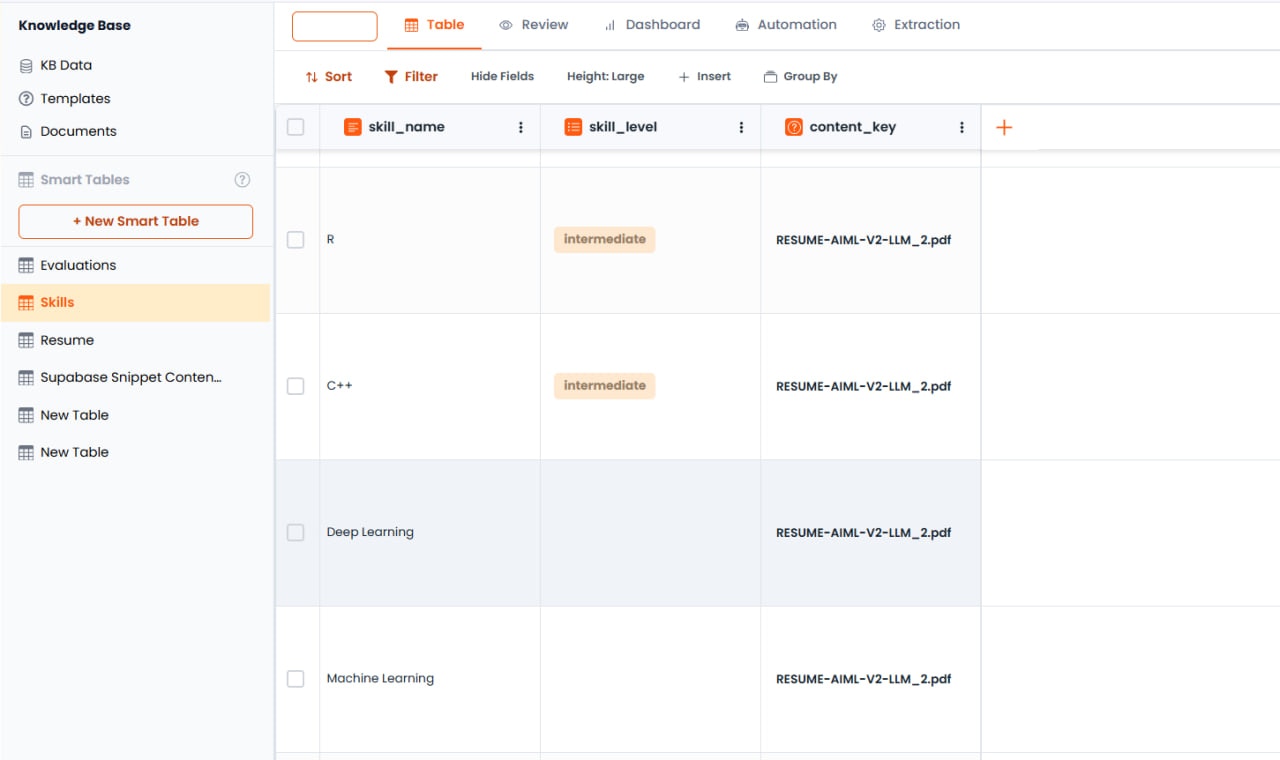
コレクションは、スマートテーブル間の多対多マッピングを可能にします。これは、メインテーブルの1行に複雑なリストデータが含まれ、独自の構造が必要な場合に便利です。例:スキルマッピング
スキルを単純なカンマ区切り文字列(例:「Python, Java」)として保存する代わりに、詳細なスキル情報を含むリレーショナル構造を作成できます:-
「スキル」テーブルを作成 — カラムを定義:
- スキル名(テキスト) — ユーザーが持つスキルの名前
- スキルレベル(単一選択) — オプション:初級、中級、上級
- メインテーブルを設定 — 「履歴書」テーブルに「スキル」という名前のカラムを作成します。
- 型をコレクションに設定 — カラムの型をコレクションに設定し、「スキル」スマートテーブルにリンクします。
-
結果 — 履歴書が処理されると、システムはスキルを抽出し、「スキル」テーブルに詳細な行(例:「Python - 上級」、「Java - 初級」、「AWS - 中級」)を入力し、多対多リレーションシップを通じて特定の候補者にリンクします。
コレクションデータの表示
メインテーブル(例:履歴書)を表示する際、コレクションフィールドには関連エントリへのリンクが表示されます。リンクをクリックすると、リンクされたテーブル(例:スキル)に移動し、その候補者のすべての詳細エントリを表示できます。リレーションシップは双方向です — スキルテーブルのコンテンツキーを確認することで、各スキルがどの履歴書に属しているかを確認できます。データ管理
データが入力された後、データを管理・整理するためのいくつかのツールがあります。ビューとタブ
スマートテーブルは2つのビューを提供します:- テーブルビュー — 行と列を表示・編集するためのデフォルトのスプレッドシートライクなビュー
-
ダッシュボードビュー — チャートやウィジェットを作成してデータを分析する可視化ビュー
行の追加と管理
- 行を挿入 — 行を追加または行を挿入をクリックして、新しい空の行を手動で追加
-
自動行作成 — ドキュメントがアップロードされてスマートテーブルに割り当てられると、新しい行が自動的に作成され、抽出されたデータが入力されます
編集と再計算
- 手動編集 — 任意のセルをクリックして値を手動で更新
- セル/行を実行 — LLM生成またはエージェント生成フィールドについて、セルを実行または行を実行をクリックして、その行のデータを計算または更新
-
すべて再計算 — すべての行を同時に更新します。カラムの説明やエージェント設定を更新した後、データセット全体を再処理する場合に便利です
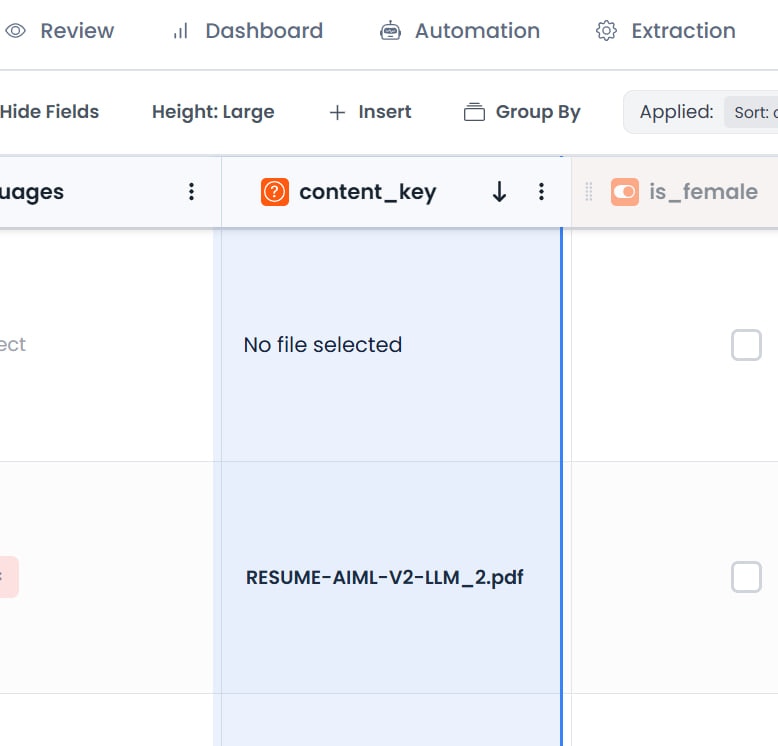
各行には、ソースドキュメントへのリンクとなる一意のコンテンツキー識別子が自動的に割り当てられます。これにより、抽出されたデータと元のファイル間のトレーサビリティが実現されます。
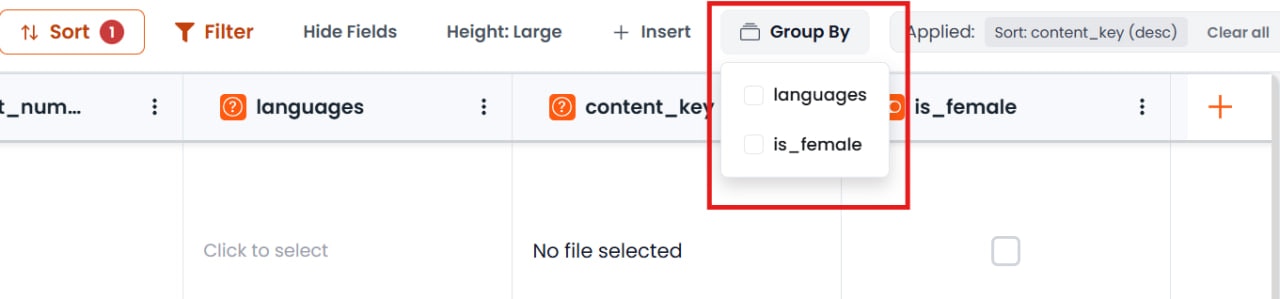
グループ化と整理
特定のカラムでデータをグループ化してビューを整理できます。例えば、候補者リストを「言語」複数選択フィールドでグループ化すると、すべてのPython開発者を一覧できます。また、テーブルビューでドラッグ&ドロップしてカラムを再配置することもできます。スマートテーブルの名前変更
上部のテーブル名をクリックして新しい名前を入力します。これにより、説明的な識別子(例:「履歴書」、「スキル」、「評価」)で複数のテーブルを整理できます。フィールドと行の削除
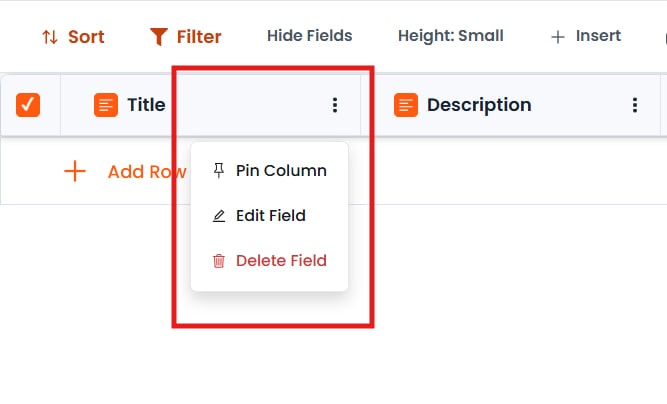
- カラムを削除 — カラム設定を編集する際、フィールドを削除を選択してカラムを完全に削除
- 行を削除 — 行をクリックして削除を選択し、個別のエントリを削除
ダッシュボードと可視化
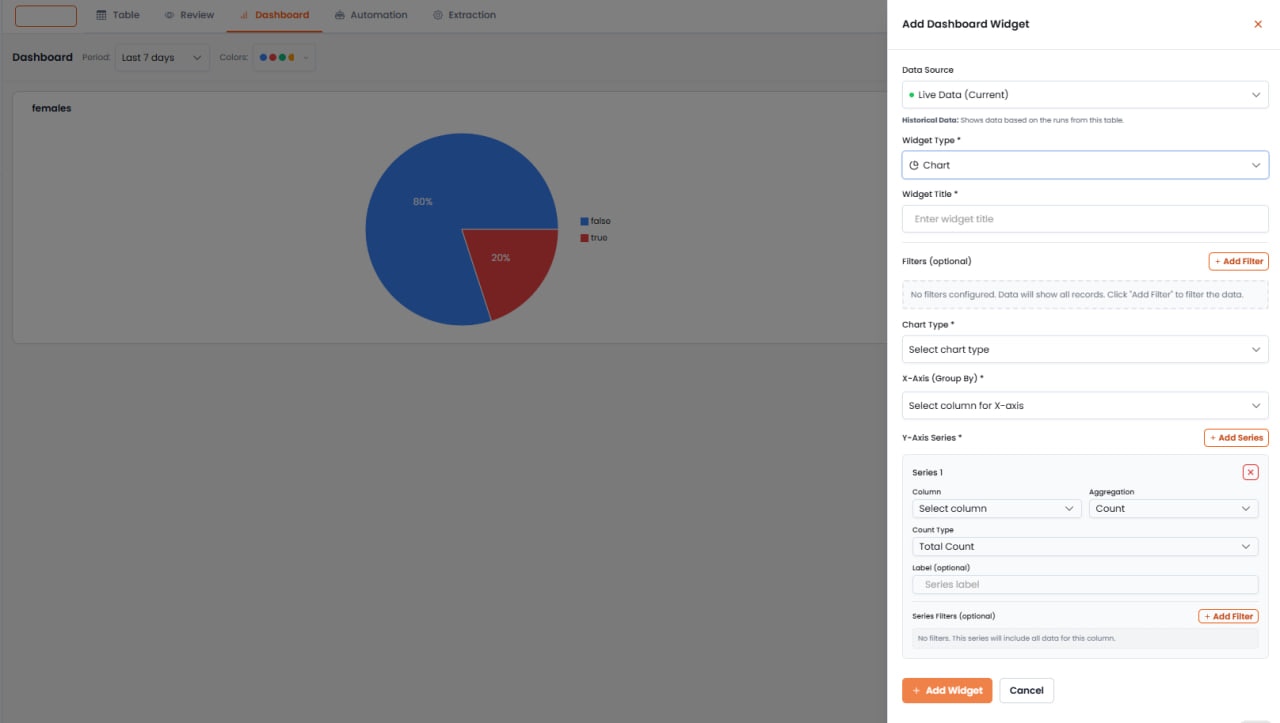
スマートテーブルには、保存されたデータを可視化するための内蔵ダッシュボードビューが含まれています。ウィジェットの作成
- スマートテーブルのダッシュボードタブに移動します
- ウィジェットを追加をクリックします
-
チャートを設定します:
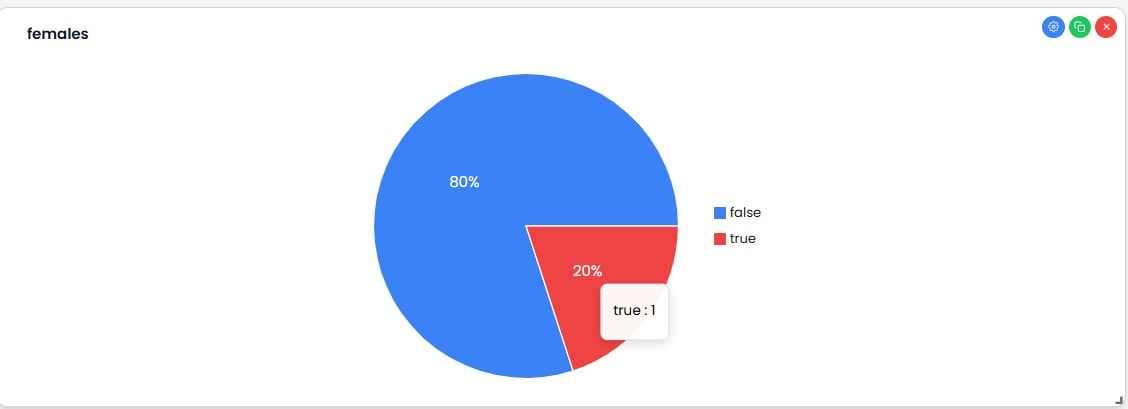
- ウィジェットタイトル — 説明的なタイトルを入力します(例:「性別ごとの候補者合計」)
- チャートの種類 — 円グラフ、棒グラフ、折れ線グラフなどから選択
- X軸(カテゴリ) — グループ化フィールドを選択します(例:女性かどうか)
- Y軸(値) — 計測する指標を選択し、カウント、合計、平均などの集計関数を使用
- Yシリーズカラム名 — オプションでチャート凡例に表示されるラベルをカスタマイズ
-
ウィジェットを保存してダッシュボードに追加します
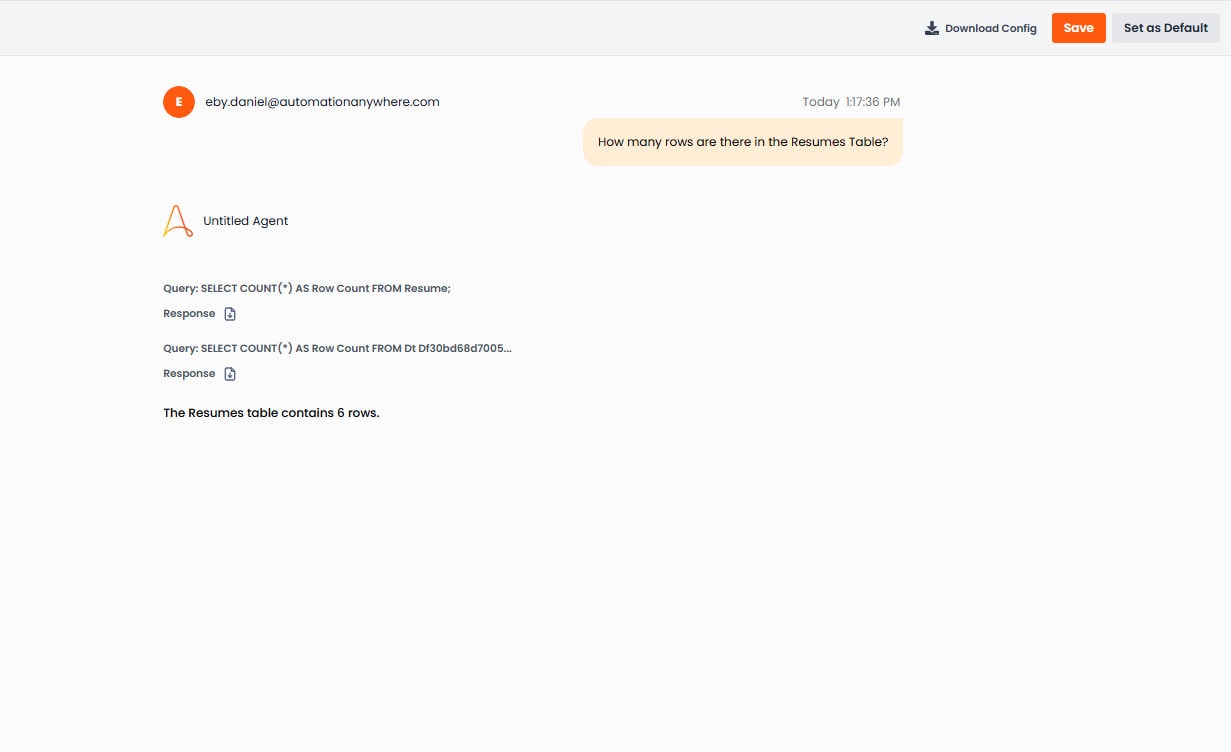
エージェントを通じたスマートテーブルのクエリ
スマートテーブルの最も強力な機能の1つは、エージェントを通じて自然言語で構造化データをクエリできる ability です。セットアッププロセス
1
エージェントの作成
エージェントビルダーに移動し、新しいエージェントを作成するか、既存のエージェントを開きます。
2
ツールキットの設定
エージェントにデータベースマネージャーツールキットを追加します。
3
スマートテーブルの選択
ツールキット設定で、エージェントがアクセスできるスマートテーブルを1つ以上選択します。これにより、エージェントは複数の関連テーブルにまたがってクエリを実行できます。
4
クエリオプションの設定
エージェントがスマートテーブルデータのみにアクセスする場合のみ、「データベースクエリ」や「データベーススキーマ」など、不要なオプションの選択を解除します。
5
保存とテスト
エージェントチャットを開き、自然言語で質問します。例:
- 「5年以上の経験を持つ候補者は何人いますか?」
- 「Pythonのエキスパートをすべて一覧表示してください」
- 「履歴書テーブルには何行ありますか?」
テンプレート
テンプレートは、一般的なユースケース向けに事前設定されたカラム構造を提供し、セットアップを加速します。既存のテンプレートから選択できますが、UIを通じてカスタムテンプレートを作成することはできません。評価テンプレート
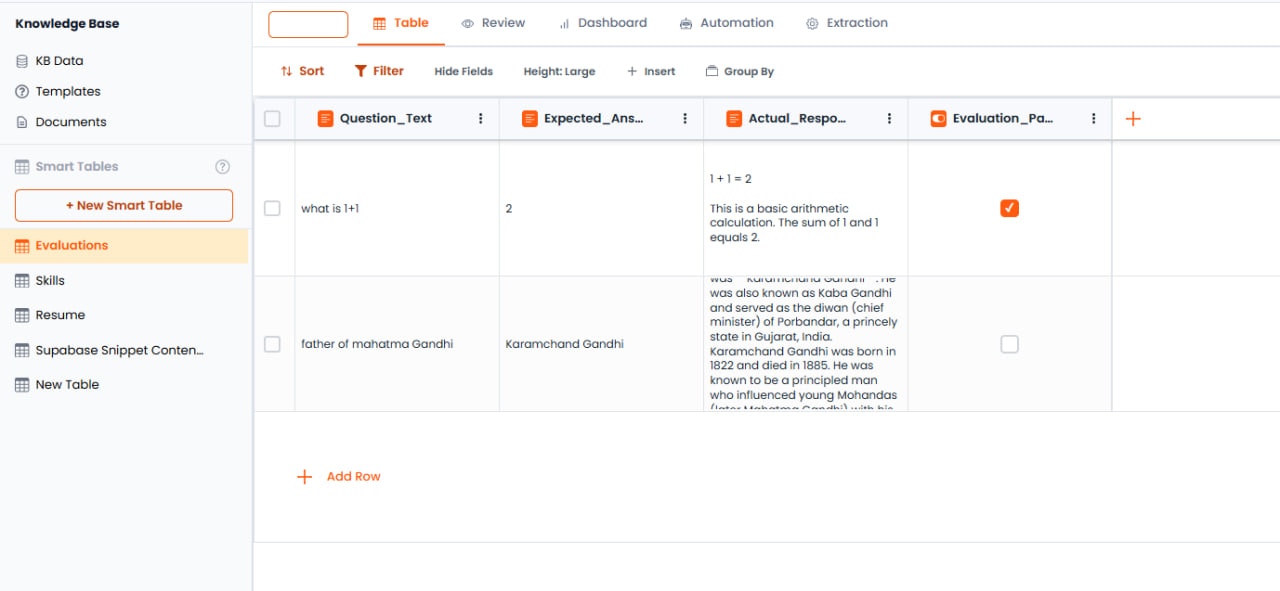
エージェントのパフォーマンスをテストし、AIの応答を検証するために設計されています。以下が含まれます:- 質問テキスト — エージェントへの入力プロンプト(ユーザー入力)
- 期待される回答 — グラウンドトゥルースまたは正解(ユーザー入力)
- 実際の応答 — 評価実行中にエージェントによって入力されます(エージェント生成)
- 評価ステータス — 実際の応答と期待される回答を比較し、合格/不合格の割合を返します(比較)
- 評価テンプレートからスマートテーブルを作成
- テスト質問と期待される回答を含む行を追加
- エージェントフィールドを設定してAIエージェントに接続
- 個別の行を実行するか、すべて再計算を実行してすべての質問をテスト
-
実際の応答と評価ステータスを確認してエージェントのパフォーマンスを評価
ベストプラクティス
- カラムの説明 — 各カラムに明確で説明的なテキストを記述して、抽出時にLLMを導きます。例えば、「経験年数」というカラム名に次のように追加します:「履歴書に記載されている專業的な仕事経験の総年数」。
- データ型 — 正確なソート、フィルタリング、チャート作成を可能にするために、具体的な型(数値 vs. テキスト)を使用します。「経験年数」にはテキストではなく数値を使用してください。
- フォーマットの選択 — フィールドの種類に応じて適切なフォーマットを選択します。連絡先フィールドには電話番号フォーマットを使用し、金額には通貨フォーマットを使用してください。
- コレクション — 複雑なリスト(スキル、資格、学歴)にはコレクションを使用して、データの整合性を維持し、より深いクエリを可能にします。
- テスト — バルクアップロード前に、1〜2つのドキュメントでテストして、カラムの説明が正しくAIを導いていることを確認してください。
- クイックアップロード — アップロード時にスマートテーブルを割り当てる際、クイックアップロードを有効にしてデータを即座に抽出・入力してください。
- 抽出の再適用 — カラムの定義を変更した場合、更新された設定で再抽出するために、既存のドキュメントにスマートテーブルを再割り当てしてください。
- 比較フィールド — Q&Aワークフローでの期待値と実際の結果の比較など、検証シナリオには比較を使用してください。
スマートテーブルは**ワークフロー(アクション)**をトリガーして対話することもでき、「履歴書が条件を満たしたらメールを送信する」などの高度なロジックを実現します。詳細については、ワークフロー自動化のドキュメントを参照してください。