ナビゲーション
ナレッジベースは、左側のサイドバーからナレッジベースをクリックしてアクセスできます。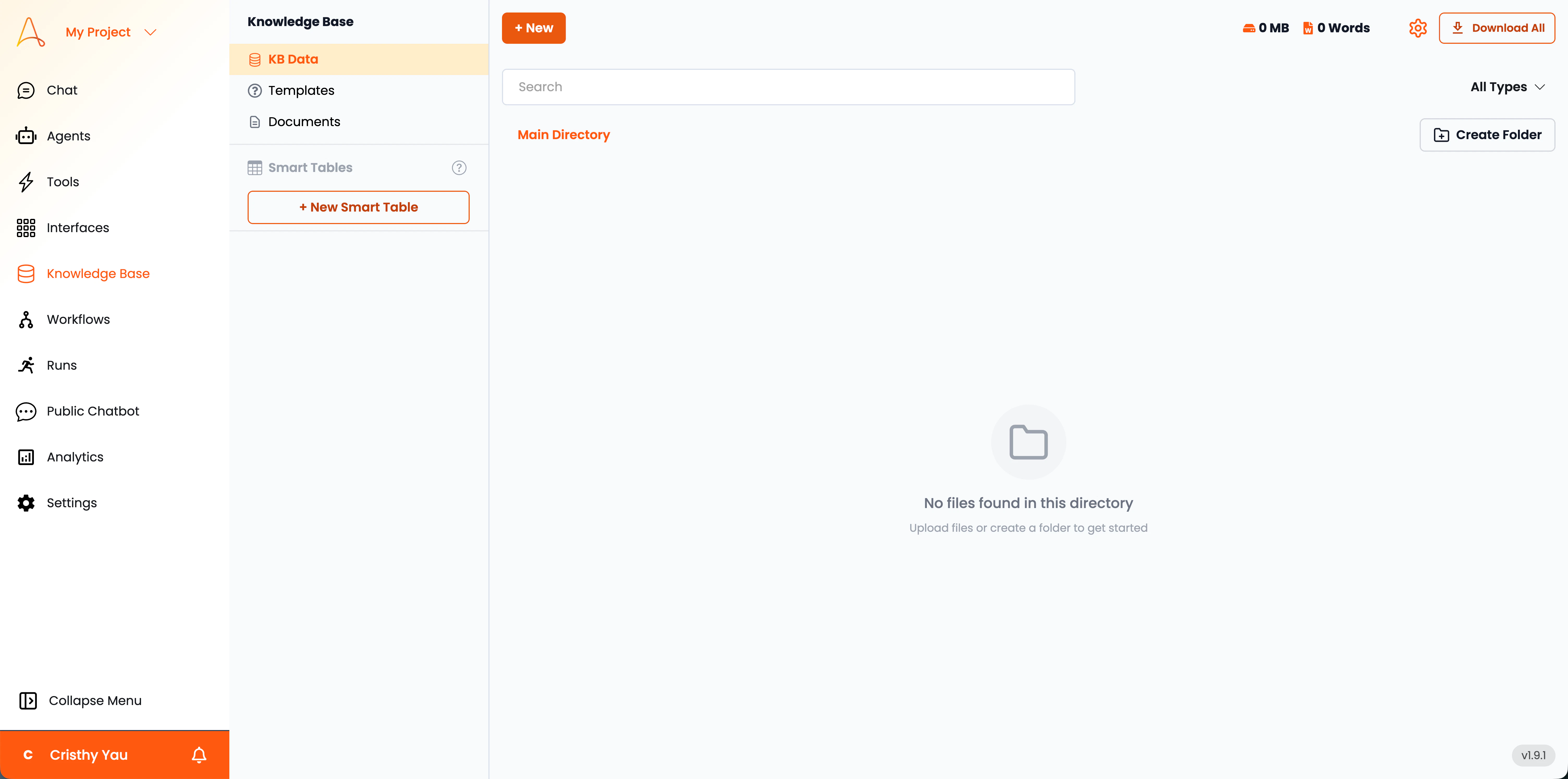
KBデータ
KBデータ
KBデータは、取得されたすべての情報が格納される主要リポジトリとして機能します。ここでは、ナレッジベースデータの表示、管理、整理が可能です。このセクションには、アップロードされたドキュメント、ウェブクロール、およびサードパーティ連携から取得したデータが含まれます。
KBデータセクションの主な機能をご紹介します:
- メインディレクトリ:メインディレクトリは、すべてのナレッジベースデータを構造化された形式で表示します。ドキュメントの一覧、その種類、その他の関連詳細を確認できます。
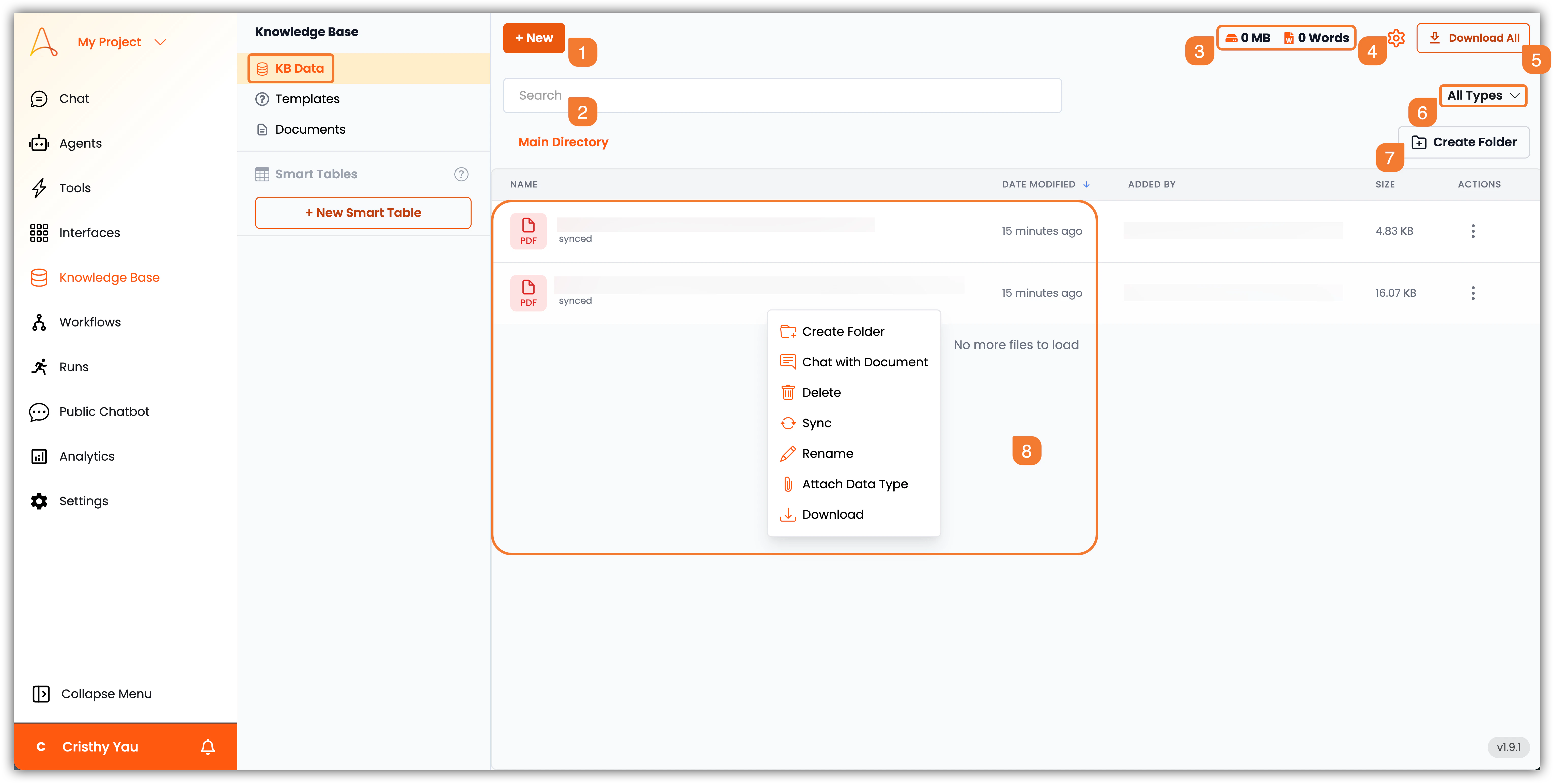
- +新規:このボタンをクリックして、新しいナレッジベースデータを追加します。ファイルやフォルダをアップロードしたり、ウェブクロールを開始したり、URLからデータをアップロードしたり、ドキュメントを作成したりできます。
- 検索バー:検索バーを使用して、ナレッジベース内の特定のドキュメントや情報をすばやく検索できます。
- ストレージと文字数:このセクションには、使用されている合計ストレージ量とナレッジベースデータの文字数が表示されます。
- 設定:設定アイコンをクリックして、ナレッジベースがドキュメントを処理および埋め込む方法を設定します。これにより、コンテンツのチャンク分割、埋め込み、取得方法が変更されます。このセクションから、コネクター(サードパーティ連携)、クローラー、および接続されたサードパーティアプリとのナレッジベースの同期とスケジュール管理も行えます。
- すべてダウンロード:このボタンをクリックすると、すべてのナレッジベースデータをZIPファイルとしてダウンロードできます。
- ファイルフィルター:ファイルフィルターを使用して、種類別にドキュメントを表示できます:PDF、Word、Excel、PowerPoint、テキスト、CSVなど。
- フォルダ作成:このボタンをクリックして、ナレッジベースデータを整理するための新しいフォルダを作成します。
- ファイル一覧:このセクションには、ナレッジベース内のファイルとフォルダの一覧が表示されます。ファイルをクリックして、そのコンテンツとメタデータを表示できます。ファイルやフォルダを右クリックすると、以下の追加オプションにアクセスできます:
- フォルダ作成:現在のディレクトリ内に新しいフォルダを作成します。
- ドキュメントとチャット:選択したドキュメントのコンテンツとやり取りするためのチャットインターフェースを開きます。
- 削除:選択したファイルまたはフォルダをナレッジベースから削除します。
- 同期:選択したファイルまたはフォルダを手動で同期し、ファイル内のコンテンツを再処理します。
- データ型の添付:このオプションにより、選択したファイルにデータスキーマを添付し、構造化データの抽出と照会機能を有効にできます。
- ダウンロード:選択したファイルをローカルデバイスにダウンロードします。
- ナレッジベース設定:設定できる主な項目は以下の通りです:
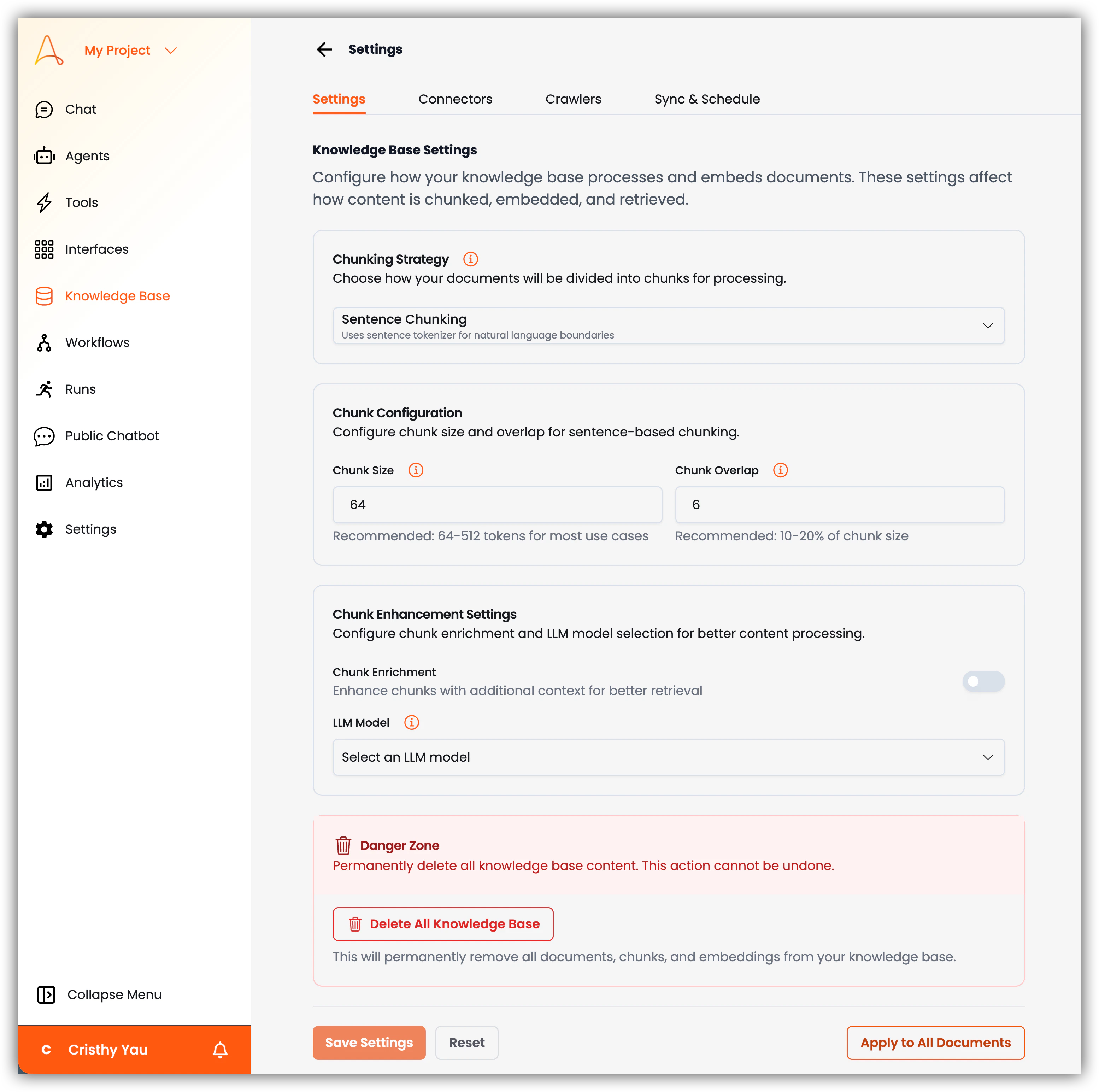
- チャンク分割戦略:ドキュメントを処理用にどのようにチャンクに分割するかを設定します。以下のオプションから選択できます:
- 文チャンク分割:文の境界に基づいてテキストをチャンクに分割し、各チャンクに完全な文が含まれるようにします。このオプションは、自然言語の境界を検出するために文トークナイザーを使用します。
- セマンティックチャンク分割:文の境界に一致しない場合もある、意味的に有意義なチャンクにテキストを分割します。このオプションは、自然言語の境界を検出するためにセマンティックトークナイザーを使用します。
- チャンク設定:_文チャンク分割_を選択すると、この設定が表示されます。ここでは、文ベースのチャンク分割のチャンクサイズとオーバーラップを設定できます。
- チャンクサイズ:各チャンクの最大サイズをトークン/文字数で指定します。デフォルトは
64です。ほとんどのユースケースでは、64〜512トークンを推奨します。大きなチャンクはコンテキストを保持しますが、取得の精度が低下する場合があります。 - チャンクオーバーラップ:連続するチャンク間の重複単語数を指定します。これにより、チャンク境界を越えたコンテキストの維持が可能になります。デフォルトは
16です。設定したチャンクサイズの10〜20%を推奨します。 - チャンク強化設定:この設定を有効にすると、より良い取得のために追加のコンテキストでチャンク分割を強化できます。有効にすると、チャンクの充実化とコンテンツ分析のためにLLMモデルを選択できます。
- チャンクサイズ:各チャンクの最大サイズをトークン/文字数で指定します。デフォルトは
- コネクター:Google Drive、SharePoint、Confluence、Zoominなどのサードパーティ連携を管理します。
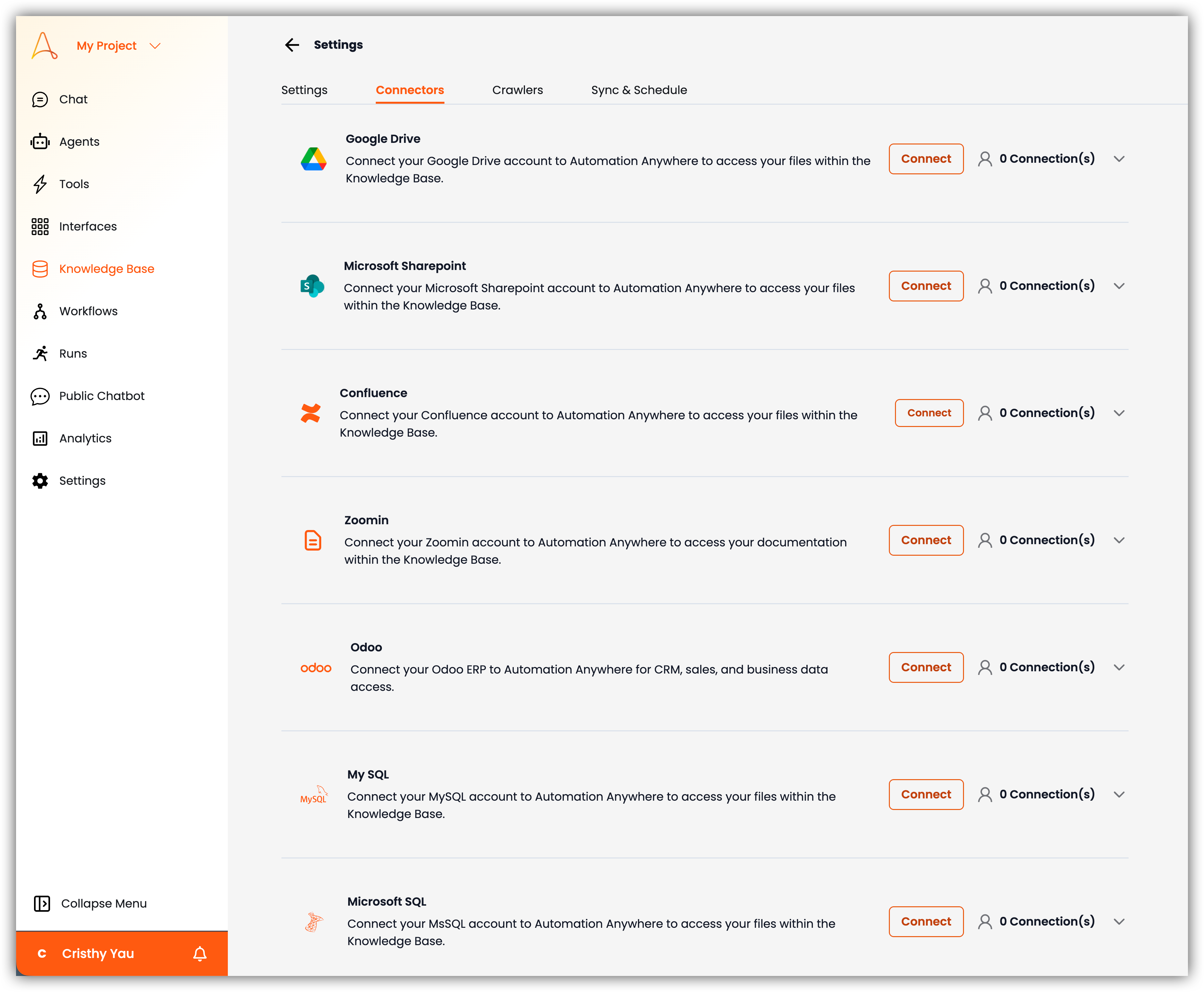
- クローラー:ウェブサイトのドメインURLからデータを取得する新しいウェブクローラーを作成します。クローラーがウェブサイト内で検出できるページはすべて自動的にクロールされ、ナレッジベースに追加されます。自動クロールのスケジュールを設定し、新しく追加されたページからの最新情報を自動的に追加することもできます。
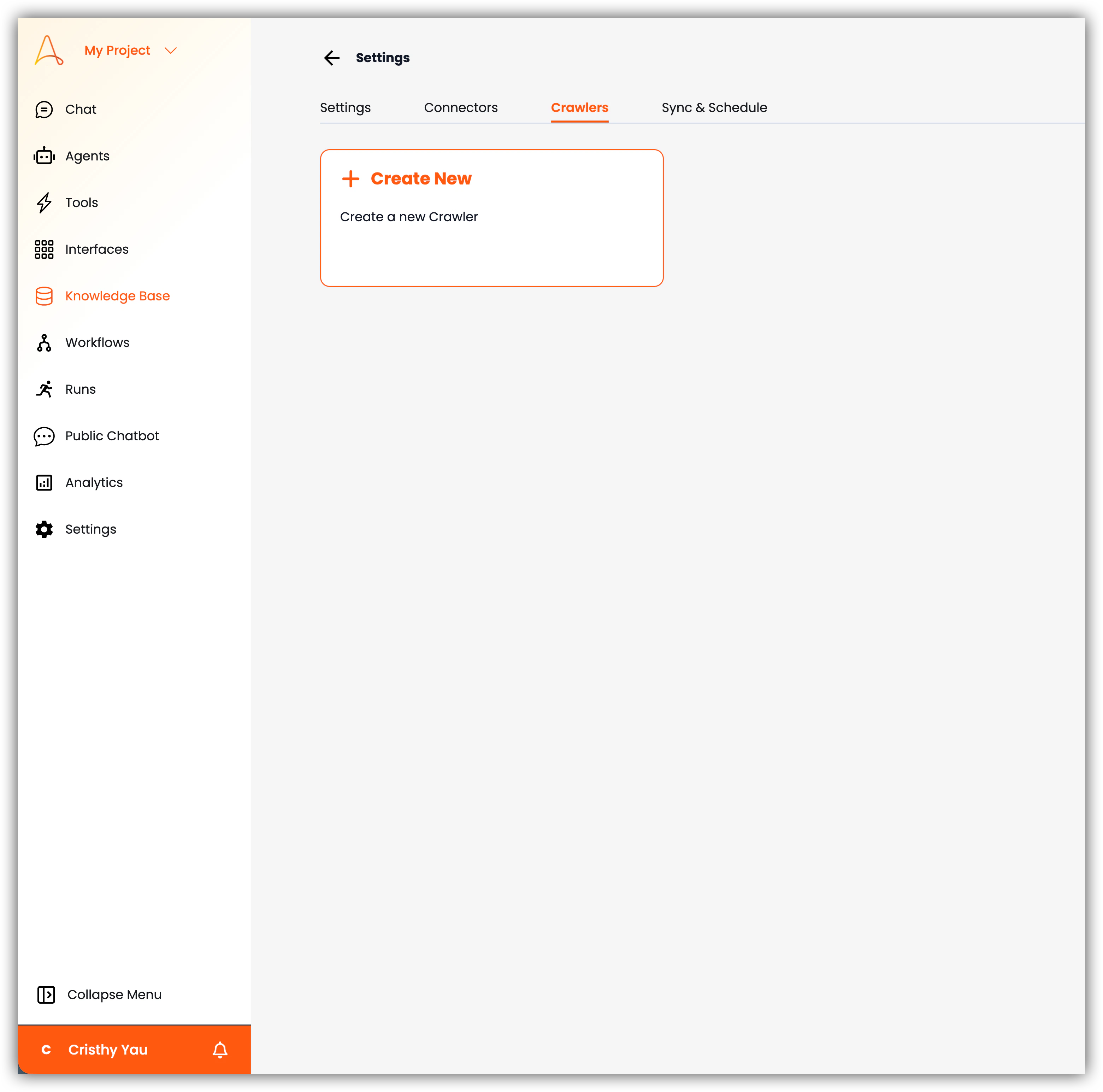
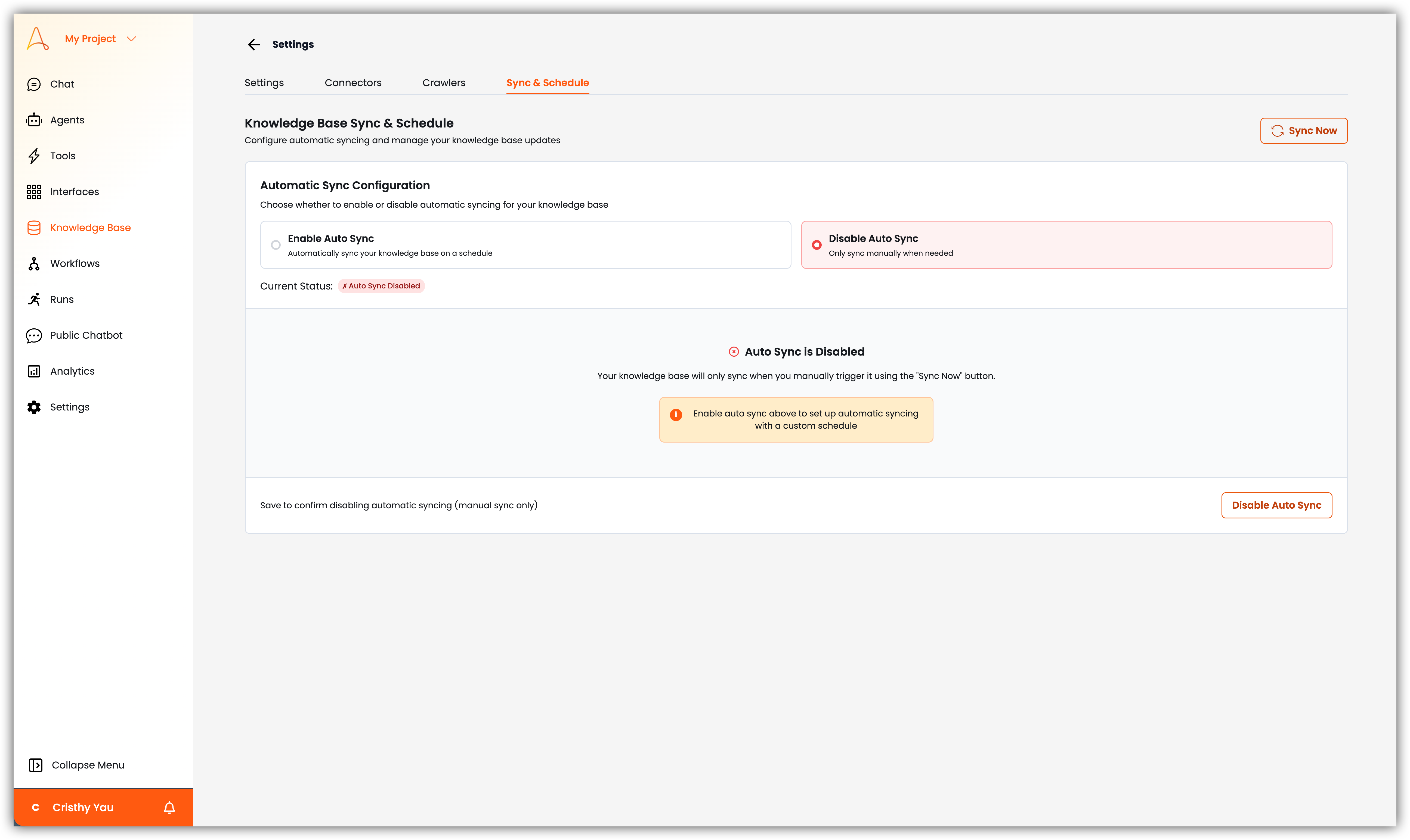
- 同期とスケジュール:ナレッジベースの同期およびスケジュール設定を管理します。ここでは、サードパーティ連携の同期スケジュールの表示と管理、手動同期による最新データの取得が可能です。
- チャンク分割戦略:ドキュメントを処理用にどのようにチャンクに分割するかを設定します。以下のオプションから選択できます:
テンプレート
テンプレート
テンプレートは、Q&Aのペア、レスポンステンプレート、および事例を定義できるもので、AIエージェントが完全なドキュメントから回答を検索する代わりに、これらのテンプレートを使用してより正確で文脈に沿ったレスポンスを生成するのを支援します。これにより、レスポンスが高速になります。特定のユースケースに合わせてテンプレートを作成、管理、整理できます。FAQ形式のテンプレートでは、AIエージェントに追加のコンテキストを提供するために、ナレッジベースからファイルを関連付けることもできます。
テンプレートセクションの主な機能をご紹介します:
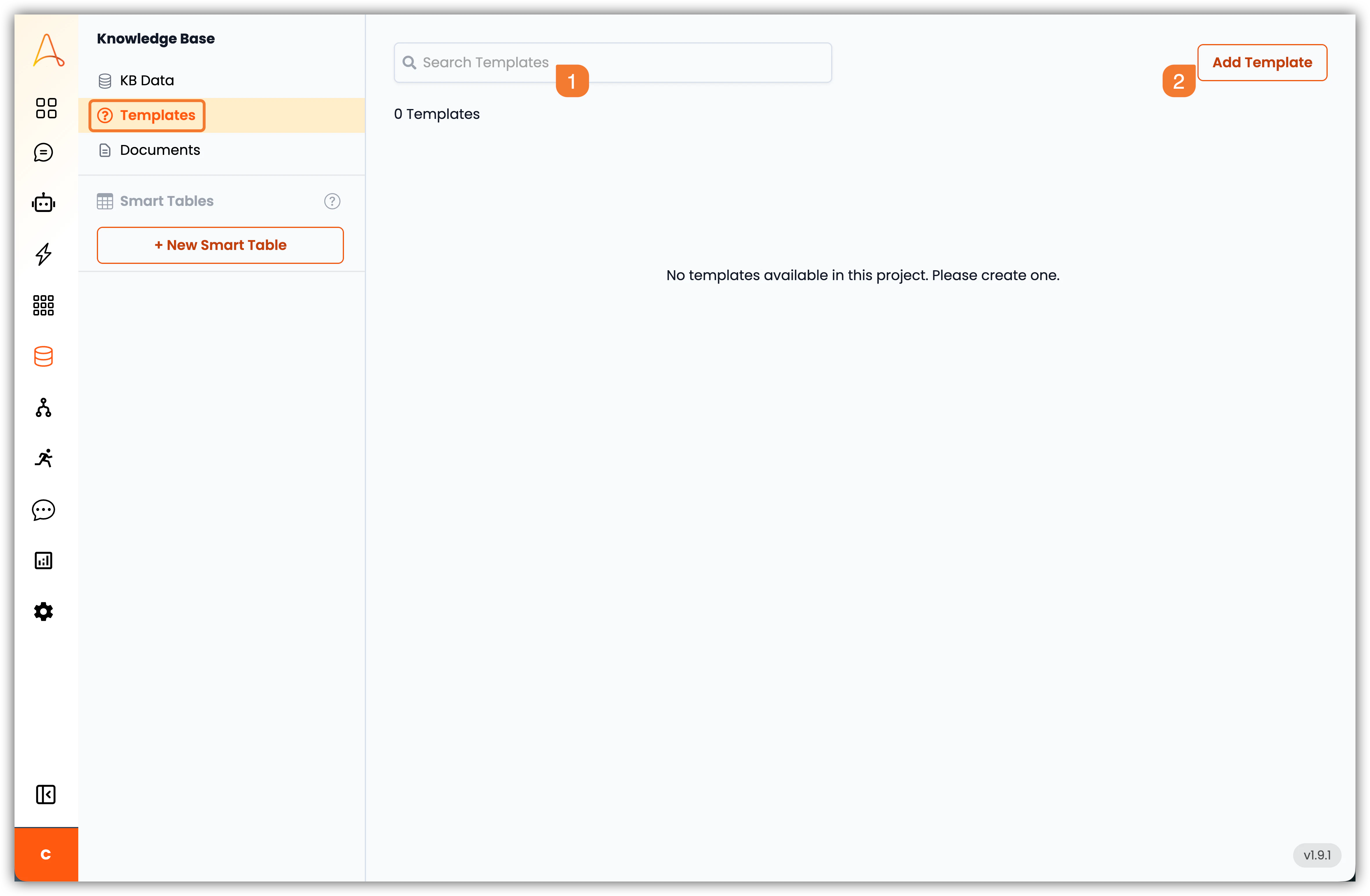
- 検索バー:検索バーを使用して、ナレッジベース内の特定のテンプレートをすばやく検索できます。
- テンプレート追加:このボタンをクリックして、新しいテンプレートを作成します。タイプ(FAQ、テンプレート、または事例)、コンテンツを定義し、追加のコンテキストとしてナレッジベースからファイルを関連付けることができます。
ドキュメント
ドキュメント
ドキュメントセクションでは、アップロードすることなく、ナレッジベース内で直接新しいテキストベースのファイルを作成できます。この機能により、ドキュメントの作成、編集、およびAI主導のナレッジ取得とのシームレスな統合が可能になります。
ドキュメントセクションの主な機能をご紹介します:
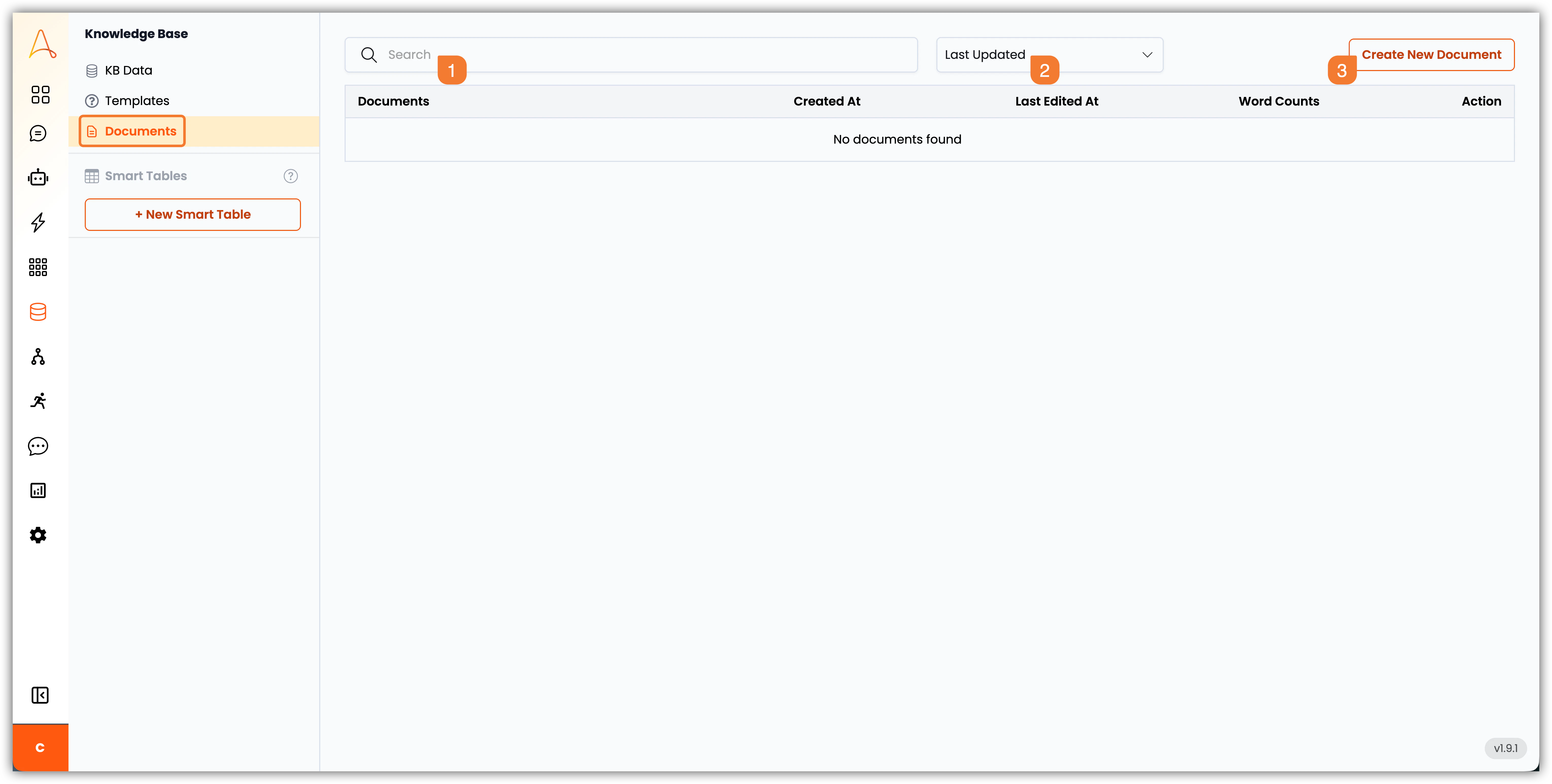
- 検索バー:検索バーを使用して、特定のドキュメントをすばやく検索できます。
- フィルター:フィルターを使用して、
最終更新日、作成日、タイトル、または文字数でドキュメントを表示できます。 - 新しいドキュメントを作成:このボタンをクリックして、新しいドキュメントを作成します。
スマートテーブル
スマートテーブル
スマートテーブル
スマートテーブルは、PDF、DOCX、スキャンされたドキュメントなどの非構造化ソースから特に構造化データを保存、整理、抽出するために構築された、動的でスプレッドシートのようなテーブルです。単なるテーブル以上であり、ドキュメントをアップロードし、AIを使用して主要データを抽出し、意思決定と自動シームレスにできるようデータを構造化するインテリジェントなワークスペースです。その応用は無限です!スマートテーブルセクションの主な機能をご紹介します:
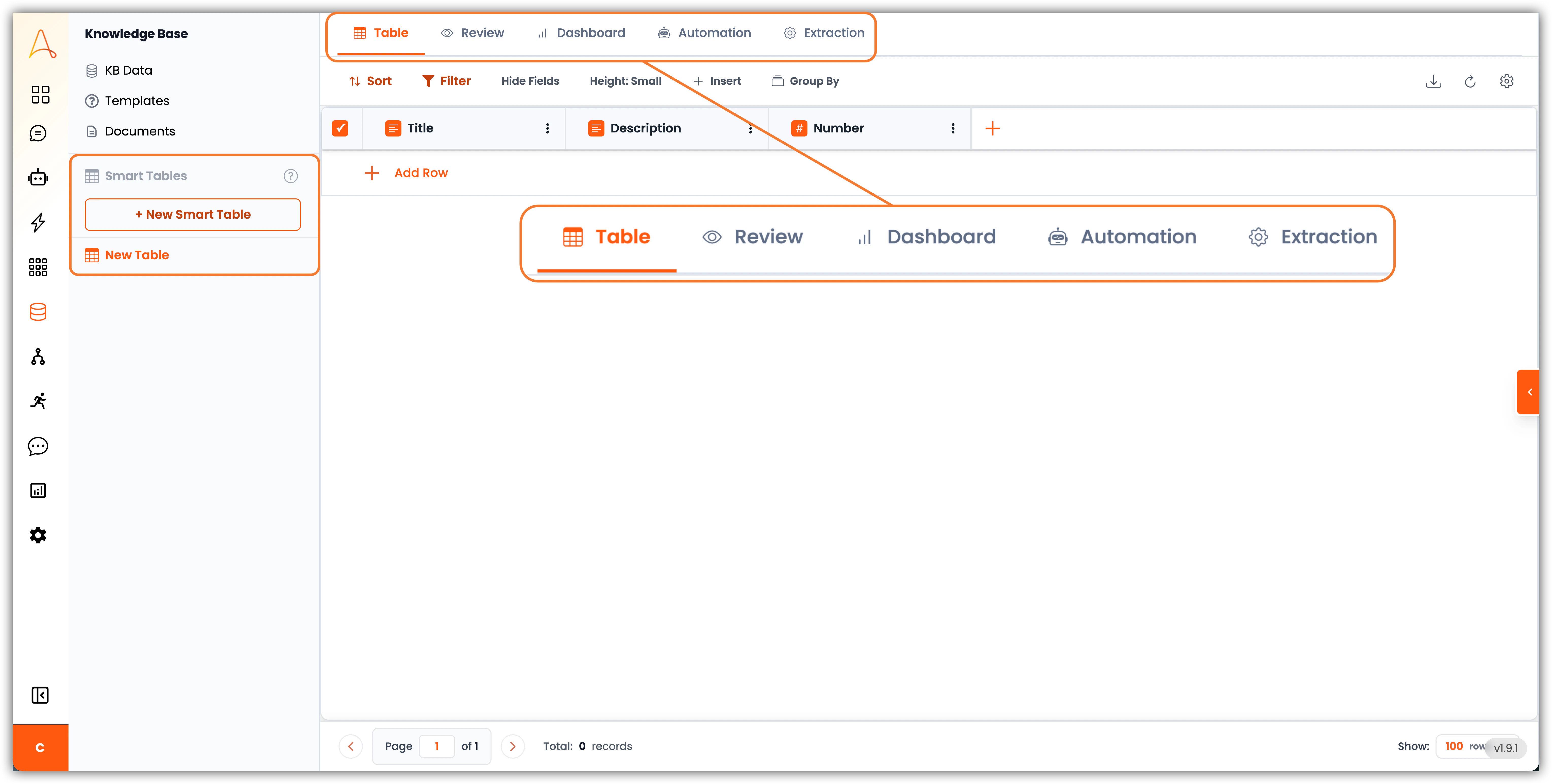
- ナビゲーション – 左側には**+ 新しいスマートテーブル**ボタンと、以前に作成したスマートテーブルの一覧があります。ボタンにマウスを合わせると、新しいテーブルを作成するためのいくつかのオプションが表示されます:
- 空のテーブルを作成
- ファイルからインポート
- テンプレートから作成
- テーブルタブ – スプレッドシート形式のビューでスマートテーブル内のすべてのデータを確認できるメインページです。すべての行とフィールドを明確に確認でき、データの直接的な整理と編集に最適です。
- レビュータブ – このビューは、承認前の抽出データの検証やモデレーションに役立つ、ヒューマンインザループプロセス用に設計されています。
- ダッシュボード – ここでダッシュボードを作成し、チャート、カウント、統計データでデータを可視化できます。
- 自動化 – スマートテーブルでは、タスクを含むカラムを作成して値を計算したり、AIエージェントやLLMを使用して評価を行ったり、テーブル内の情報に基づいて情報を検索したりできます。自動化タブでは、これらのカラムの自動計算のためのカラム実行順序と履歴追跡を設定します。
- 抽出 – このタブはAI主導のドキュメント抽出の要です。ここでは、取得するデータの設定、テーブルカラムへのマッピング、データの抽出方法を設定できます。
ドキュメント閲覧インターフェース
ナレッジベースでドキュメントをクリックすると、ドキュメント閲覧インターフェースが開きます。ここでは、ドキュメントのメタデータと関連情報を読み取り、管理できます。インターフェースは、ドキュメントコンテンツエリアとメタデータサイドバーの2つの主要セクションに分かれています。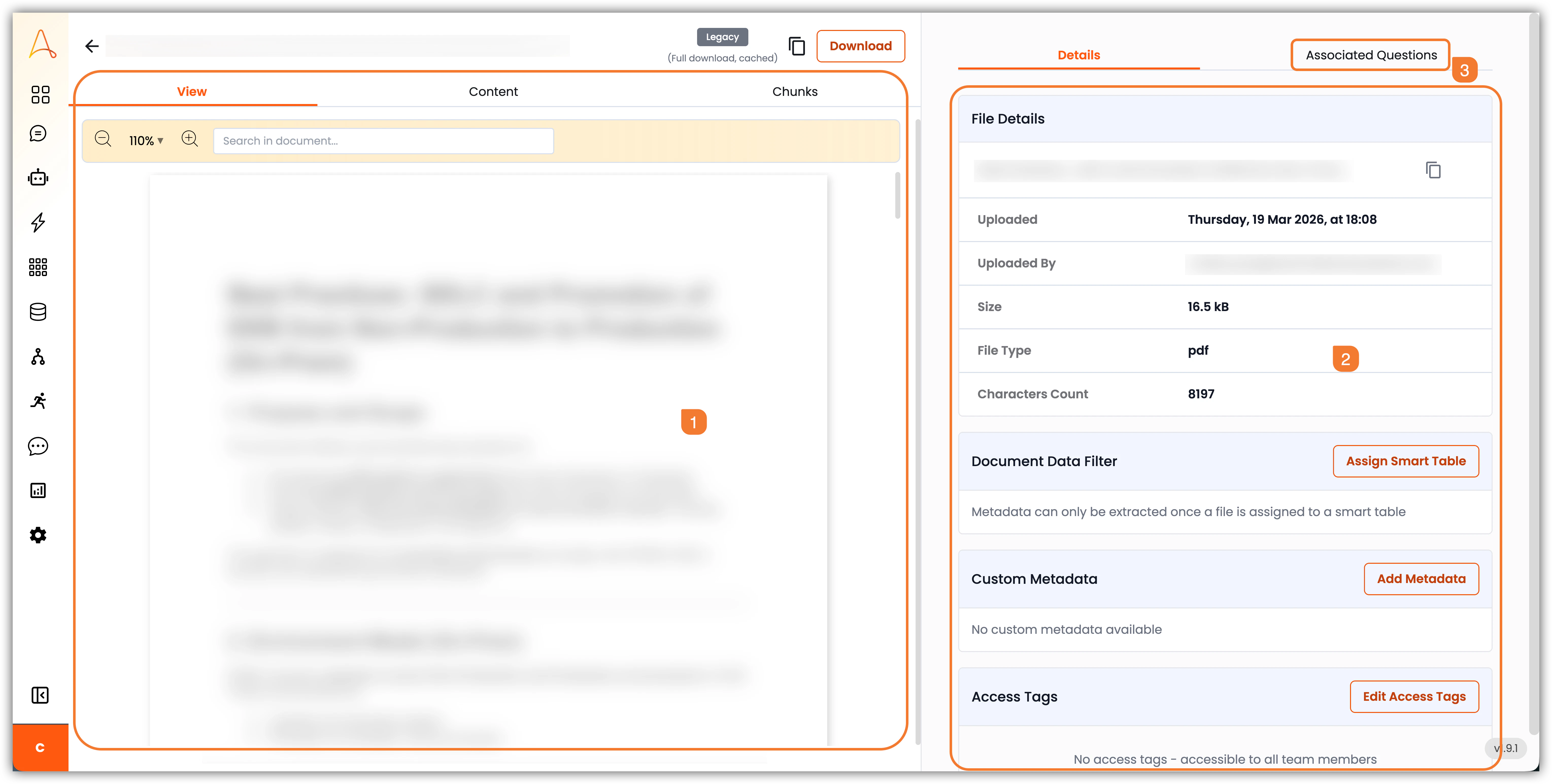
- ドキュメントコンテンツエリア:ドキュメントのメインコンテンツが表示される場所です。画面の上部には、ファイル名のコピーまたはファイルのダウンロードを行うボタンがあります。このエリアには3つのタブがあります:
a. 表示:アップロードされたままのファイルのコンテンツを表示します。
b. コンテンツ:ファイルから抽出されたテキストコンテンツを表示します。これは、AIエージェントが取得や質問応答に使用するコンテンツです。
c. チャンク:ナレッジベースの設定で構成されたチャンク分割戦略に基づいて作成された個々のテキストチャンクを表示します。各チャンクは、AIエージェントによって独立して取得できるドキュメントの小さなセグメントです。 - 詳細サイドバー:このサイドバーには、以下を含む追加情報とオプションが提供されます:
d. ファイル詳細:ファイル名、アップロード日、アップロードユーザー、ファイルサイズ、ファイルタイプ、文字数などのファイル情報を表示します。
e. ドキュメントデータフィルター:スマートテーブルのスキーマに基づいて、構造化データ抽出用にドキュメントにスマートテーブルを割り当てることができます。
f. カスタムメタデータ:ドキュメントのカテゴリ分けとAIベースの取得を向上させるために、著者名、バージョン、ページ数、解像度、寸法、コンテンツ作成者、キーワード、その他の関連情報などのカスタムメタデータフィールドをドキュメントに追加できます。
g. アクセスタグ:ドキュメントにアクセスタグを追加して、誰がドキュメントを閲覧したり操作したりできるかを制御できます。新しいタグはスーパーアドミンダッシュボードから作成できます。 - 関連質問:関連質問タブでは、ドキュメントのコンテンツで回答できる関連するよくある質問を追加できます。これにより、ドキュメントのコンテンツに基づいて正確で関連性の高い回答を提供するAIエージェントの能力が向上します。
トラブルシューティング
このセクションでは、ナレッジベースに関する一般的な問題と、問題の特定と解決を支援するLevel 1(L1)診断手順について説明します。ナレッジベースが更新されない
症状:- 新しくアップロードされたドキュメントが検索結果に表示されない
- 既存ドキュメントへの変更がAIレスポンスに反映されない
- コネクターデータが同期されない
-
同期状態を確認する
- 設定 > 同期とスケジュールに移動する
- 自動同期が有効であることを確認し、最終同期のタイムスタンプを確認する
- エラーメッセージや失敗した同期の試みがないか確認する
-
ドキュメント処理を確認する
- ナレッジベースでドキュメントを開く
- コンテンツタブを確認し、テキストが正しく抽出されたことを確認する
- チャンクタブを確認し、チャンク分割が完了したことを確認する
- ドキュメントのメタデータに処理エラーがないか確認する
-
埋め込みモデルの一貫性を確認する
- 設定 > 設定タブに移動する
- インデックス作成に使用された埋め込みモデルが、クエリに使用されるものと一致することを確認する
- ドキュメントがインデックス作成された後に埋め込みモデルが変更されていないことを確認する
-
手動同期
- ドキュメントまたはフォルダを右クリックする
- 同期を選択して手動で再処理を開始する
- 同期が完了するまで待ち、問題が解決されたか確認する
-
コネクターの状態を確認する
- コネクター(Google Drive、SharePointなど)を使用している場合、設定 > コネクターでコネクターの状態を確認する
- 認証がまだ有効であることを確認する
- 接続エラーやレート制限の警告がないか確認する
検索結果が一致しない
症状:- 検索クエリに関連ドキュメントが返されない
- AIエージェントがナレッジベースに存在する情報を見つけられない
- 不正確または無関係な検索結果
-
ドキュメントの内容を確認する
- ドキュメントを開き、コンテンツタブを確認する
- テキストコンテンツが正確で完全であることを確認する
- ドキュメントが正しく処理されたか確認する(抽出エラーがないこと)
-
チャンク分割の設定を確認する
- 設定 > 設定 > チャンク分割戦略を確認する
- チャンクサイズとオーバーラップの設定がコンテンツに適していることを確認する
- チャンクサイズが大きすぎる(特定の情報を逃す可能性)または小さすぎる(コンテキストを失う可能性)可能性を検討する
-
埋め込みモデルを確認する
- 使用中の埋め込みモデルがコンテンツタイプに適していることを確認する
- モデルがドキュメントの言語をサポートしているか確認する
- インデックス作成とクエリ間で埋め込みモデルの一貫性を確認する
-
検索クエリをテストする
- 同じクエリの異なる表現を試す
- ドキュメントのコンテンツに出現するキーワードを使用する
- 正確なフレーズ vs キーワードのどちらで検索がうまく機能するか確認する
-
ドキュメントのメタデータを確認する
- ドキュメントに割り当てられたカスタムメタデータとタグを確認する
- ドキュメントが適切にカテゴリ分けされ、タグ付けされていることを確認する
- アクセスタグが可視性を制限していないことを確認する
-
チャンクを確認する
- ドキュメントのチャンクタブを開く
- チャンクに期待される情報が含まれていることを確認する
- 関連情報が複数のチャンクに分割されていないか確認する
データが表示されない
症状:- ドキュメントがナレッジベースの一覧に表示されない
- アップロードされたファイルが表示されない
- 同期後にコネクターデータが表示されない
-
ファイルフィルターを確認する
- KBデータページの上部にあるファイルタイプフィルターを確認する
- フィルターがドキュメントタイプを除外していないことを確認する
- すべてのフィルターをクリアして、すべてのドキュメントを表示してみる
-
アップロード状態を確認する
- アップロードが正常に完了したか確認する
- アップロード中のエラーメッセージがないか確認する
- ファイルサイズと形式がサポートされていることを確認する
-
フォルダ構造を確認する
- ドキュメントがサブフォルダ内にあるか確認する
- フォルダを移動してドキュメントを検索する
- 検索バーを使用してドキュメント名で検索する
-
アクセス権限を確認する
- ドキュメントを表示する権限があることを確認する
- アクセスタグが可視性を制限していないか確認する
- 正しいアカウントでログインしていることを確認する
-
処理状態を確認する
- ドキュメントはアップロード後に処理中の場合があります
- ファイル一覧でドキュメントの状態を確認する
- 処理中の場合は数分待ってからリフレッシュする
-
コネクターの設定を確認する
- コネクターを使用している場合、コネクターの設定を確認する
- 同期用に正しいフォルダ/ファイルが選択されていることを確認する
- 同期スケジュールが正しく設定されているか確認する
その他のトラブルシューティングのヒント
- ブラウザキャッシュをクリアする:UIの問題はブラウザキャッシュのクリアで解決できる場合があります
- ブラウザコンソールを確認する:ブラウザの開発者ツール(F12)を開いて、JavaScriptエラーがないか確認する
- ネットワーク接続を確認する:同期操作の安定したインターネット接続を確認する
- システムログを確認する:EKBシステムログを確認して、バックエンドエラーがないか確認します(管理者アクセスが必要です)
- サポートにお問い合わせ:L1診断後も問題が解決しない場合は、support@automationanywhere.com に以下の情報を添えてお問い合わせください:
- 問題の説明
- 診断に実施した手順
- エラーメッセージのスクリーンショット
- 影響を受けるドキュメント/ファイル名