RAG 기술 설명
파일을 플랫폼에 업로드하면 정교한 파이프라인을 통해 처리됩니다. 먼저 텍스트 추출이 PDF, DOCX 및 기타 형식에서 원시 텍스트를 추출하고, 스캔된 이미지에는 OCR을 적용합니다. 다음으로 청킹이 텍스트를 더 작고 관리 가능한 세그먼트로 분할합니다. 그런 다음 임베딩이 임베딩 모델을 사용하여 각 청크를 벡터(의미를 나타내는 숫자 목록)로 변환합니다. 마지막으로 저장이 이러한 벡터를 벡터 데이터베이스에 저장합니다. 에이전트가 검색하면 쿼리도 임베딩되고, 데이터베이스는 쿼리와 가장 가까운 수학적 근접성(의미)을 가진 청크를 찾습니다.구성 패널
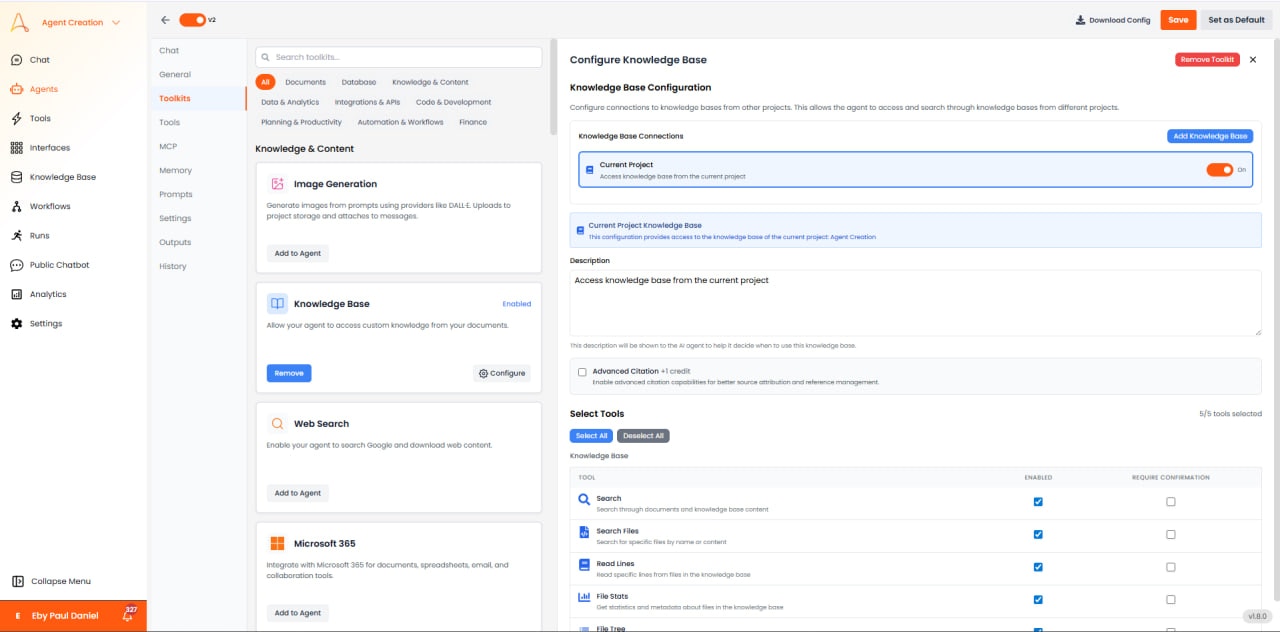
- 현재 프로젝트 Knowledge Base: 기본적으로 활성화되어 현재 워크스페이스의 파일에 접근을 허용합니다.
- 교차 프로젝트 접근: 다른 프로젝트의 KB를 연결할 수 있게 합니다 (예: 중앙 “회사 정책” 프로젝트).
- 설명: KB 내용을 설명하는 메타데이터는 에이전트가 이 도구를 사용할 시점을 결정하는 데 도움이 됩니다.
- 고급 인용 (+1 크레딧): 활성화되면 소스 텍스트에 연결된 정확한 인라인 인용을 제공합니다.
사용 가능한 하위 도구
- Search Tool: 의미 기반 검색을 위한 주요 도구. 키워드가 정확히 일치하지 않더라도 관련 정보를 찾습니다.
- Search Files Tool: 내용이 아닌 이름으로 특정 파일을 찾기 위한 메타데이터 검색.
- Read Lines Tool: 특정 파일에서 원시 텍스트를 추출합니다. 에이전트가 전체 챕터나 섹션을 자세히 읽어야 할 때 유용합니다.
- File Stats Tool: 메타데이터를 반환합니다: 파일 크기, 저자, 생성일, 페이지 수.
- File Tree Tool: 디렉토리 구조를 나열합니다. 새로운 KB를 탐색하고 파일 구조를 이해하는 데 필수적입니다.
구현 예시
- 이력서 스크리닝: 에이전트가 업로드된 모든 PDF에서 “Python 경험”을 검색하고, 다른 이력서에서 관련 청크를 검색하며, 상위 후보자를 요약합니다.
- 정책 Q&A: 사용자가 “택시비를 청구할 수 있나요?”라고 질문합니다. 에이전트가 “여행 정책”을 검색하고, 교통 섹션을 찾으며, “4.2조에 따라 고객 여행인 경우 가능합니다”라고 답변합니다.
- 기술 지원: 에이전트가 오류 코드와 문제 해결 단계를 찾기 위해 기술 매뉴얼을 검색합니다.