탐색
지식 기반은 왼쪽 사이드바에서 지식 기반을 클릭하여 접근할 수 있습니다.
KB 데이터
KB 데이터
KB 데이터는 검색된 모든 정보가 저장되는 주요 저장소 역할을 합니다. 여기서 지식 기반 데이터를 보고, 관리하고, 정리할 수 있습니다. 이 섹션에는 업로드된 문서, 웹 크롤링 및 서드파티 통합에서 가져온 데이터가 포함됩니다.
KB 데이터 섹션의 주요 기능을 살펴보겠습니다:
- 메인 디렉토리: 메인 디렉토리는 모든 지식 기반 데이터를 구조화된 형식으로 표시합니다. 문서 목록, 유형 및 기타 관련 세부 정보를 볼 수 있습니다.
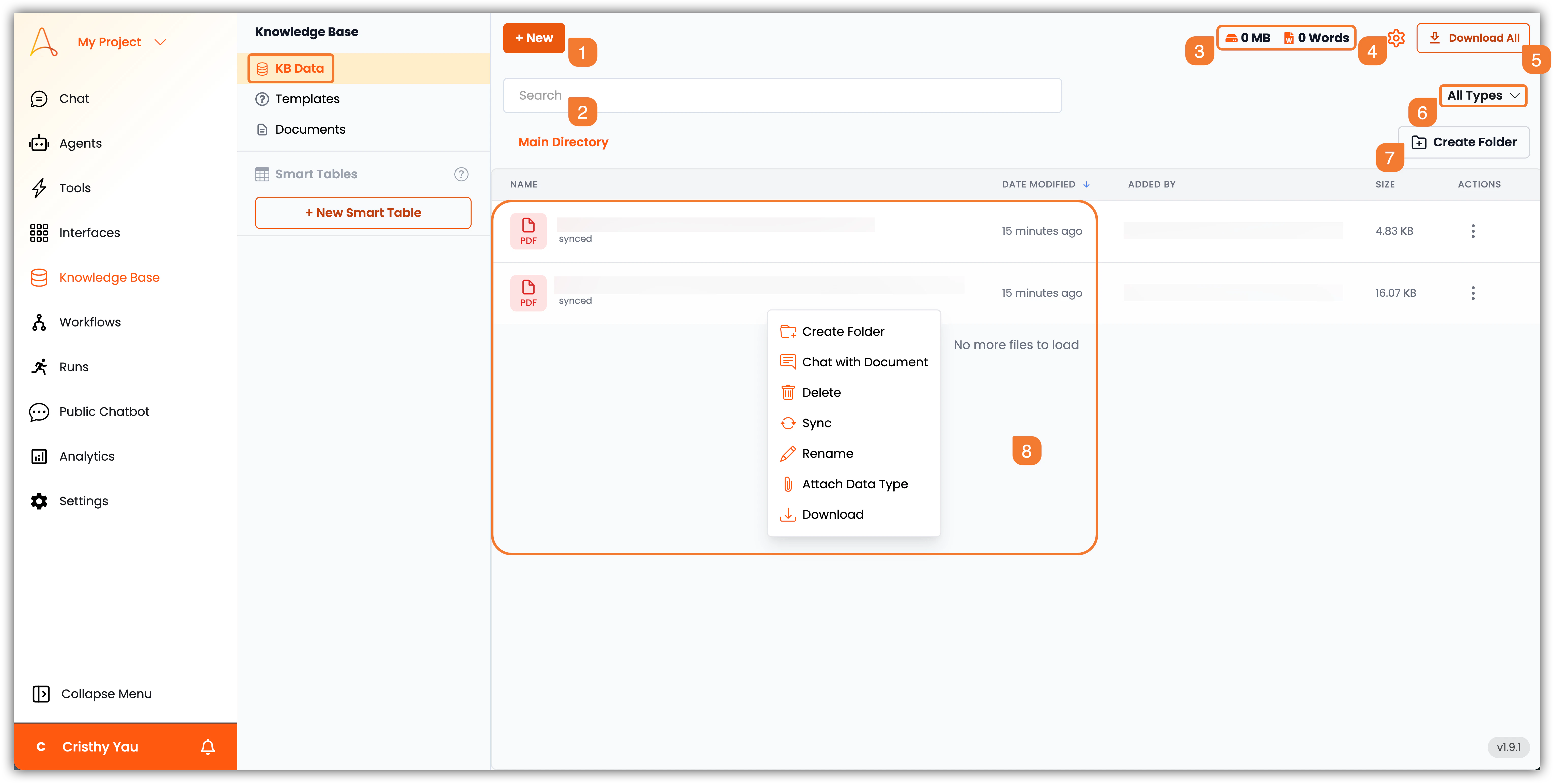
- +새로 만들기: 이 버튼을 클릭하여 새 지식 기반 데이터를 추가합니다. 파일이나 폴더를 업로드하고, 웹 크롤링을 시작하고, URL에서 데이터를 업로드하거나 문서를 만들 수 있습니다.
- 검색 표시줄: 검색 표시줄을 사용하여 지식 기반 내에서 특정 문서나 정보를 빠르게 찾을 수 있습니다.
- 저장 용량 및 단어 수: 이 섹션은 사용된 총 저장 용량과 지식 기반 데이터의 단어 수를 표시합니다.
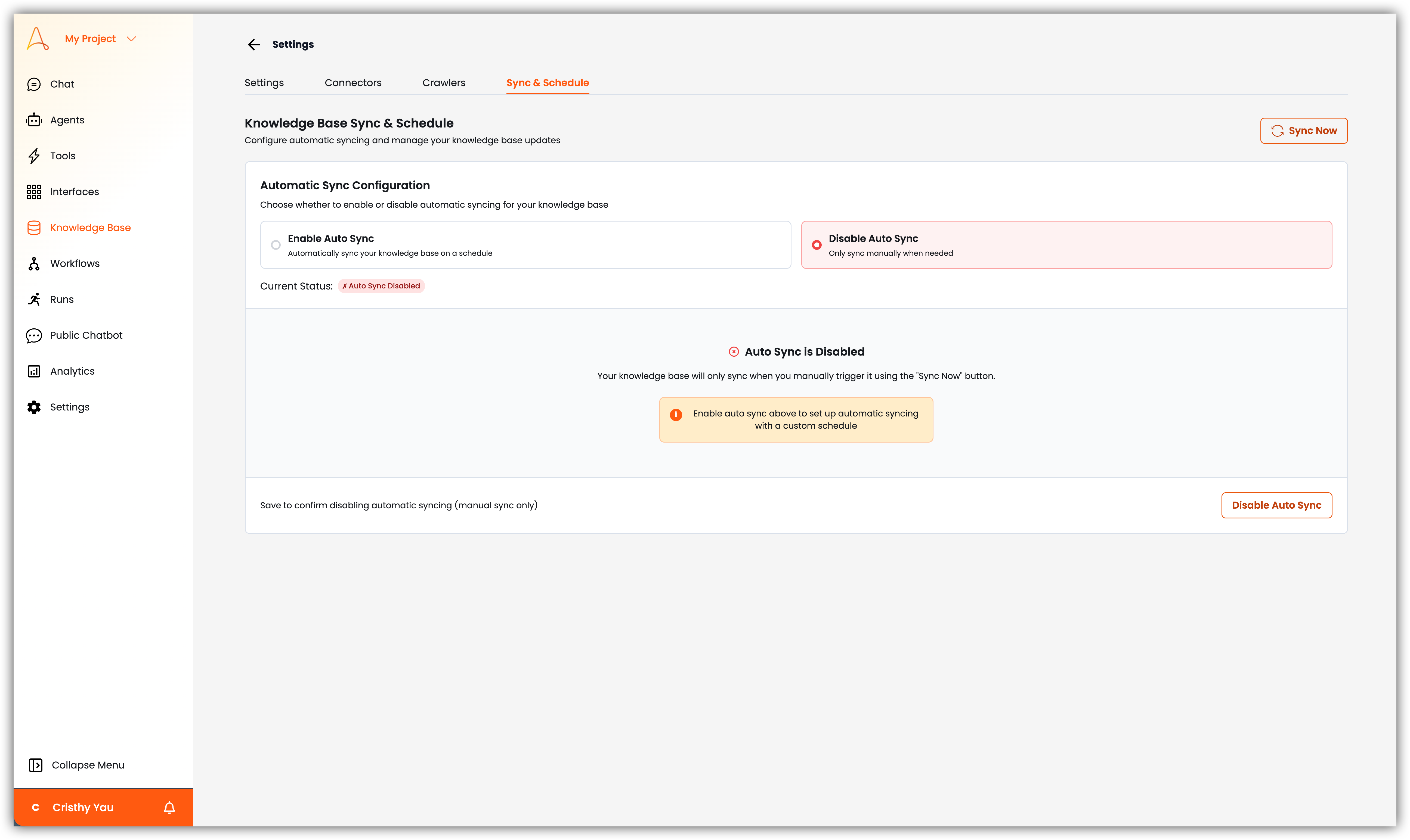
- 설정: 설정 아이콘을 클릭하여 지식 기반에서 문서를 처리하고 임베딩하는 방법을 구성할 수 있으며, 이는 콘텐츠가 청킹, 임베딩 및 검색되는 방식에 영향을 미칩니다. 이 섹션에서 커넥터(즉, 서드파티 통합), 크롤러 및 연결된 서드파티 앱과의 지식 기반 동기화 및 예약도 관리할 수 있습니다.
- 모두 다운로드: 이 버튼을 클릭하여 모든 지식 기반 데이터를 ZIP 파일로 다운로드합니다.
- 파일 필터: 파일 필터를 사용하여 유형별로 문서를 봅니다: PDF, Word, Excel, PowerPoint, Text, CSV 등.
- 폴더 만들기: 이 버튼을 클릭하여 지식 기반 데이터를 정리할 새 폴더를 만듭니다.
- 파일 목록: 이 섹션은 지식 기반의 파일 및 폴더 목록을 표시합니다. 파일을 클릭하여 내용과 메타데이터를 볼 수 있으며, 파일이나 폴더를 마우스 오른쪽 버튼으로 클릭하여 다음과 같은 추가 옵션에 접근할 수 있습니다:
- 폴더 만들기: 현재 디렉토리에 새 폴더를 만듭니다.
- 문서로 채팅: 선택한 문서의 내용과 상호작용할 수 있는 채팅 인터페이스를 엽니다.
- 삭제: 선택한 파일이나 폴더를 지식 기반에서 제거합니다.
- 동기화: 수동으로 선택한 파일이나 폴더를 동기화하여 파일의 내용을 다시 처리합니다.
- 데이터 유형 연결: 이 옵션을 사용하면 선택한 파일에 데이터 스키마를 연결하여 구조화된 데이터 추출 및 쿼리 기능을 활성화할 수 있습니다.
- 다운로드: 선택한 파일을 로컬 장치에 다운로드합니다.
- 지식 기반 설정: 구성할 수 있는 주요 설정은 다음과 같습니다:
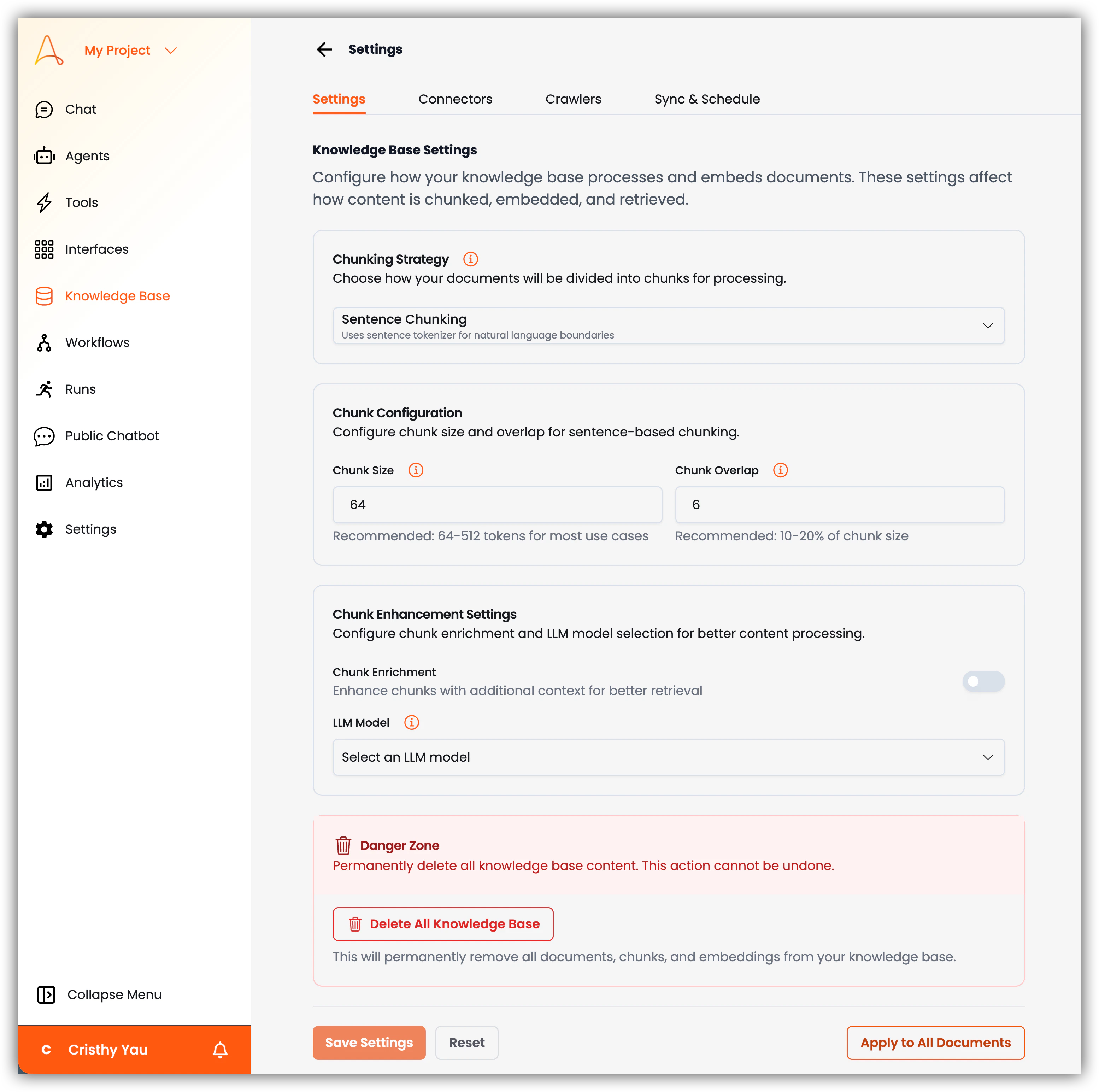
- 청킹 전략: 문서가 처리를 위해 청크로 분할되는 방법을 구성합니다. 다음 옵션 중에서 선택합니다:
- 문장 청킹: 문장 경계를 기반으로 텍스트를 청크로 분할하여 각 청크에 완전한 문장이 포함되도록 합니다. 이 옵션은 자연어 경계를 위해 문장 토크나이저를 사용합니다.
- 의미적 청킹: 문장 경계와 일치하지 않을 수 있는 의미론적으로 의미 있는 청크로 텍스트를 분할합니다. 이 옵션은 자연어 경계를 위해 의미적 토크나이저를 사용합니다.
- 청크 구성: _문장 청킹_을 선택하면 이 구성이 나타납니다. 여기서 문장 기반 청킹의 청크 크기와 겹침을 구성할 수 있습니다.
- 청크 크기: 각 청크의 최대 크기를 토큰/문자로 지정합니다. 기본값은
64입니다. 대부분의 사용 사례에 대해64에서512토큰 사이를 권장합니다. 더 큰 청크는 컨텍스트를 보존하지만 검색 정확도가 떨어질 수 있습니다. - 청크 겹침: 연속 청크 간 겹치는 단어 수를 지정합니다. 이를 통해 청크 경계 전반에 걸쳐 컨텍스트를 유지할 수 있습니다. 기본값은
16입니다. 설정된 청크 크기의 10~20%를 권장합니다. - 청크 향상 설정: 이 설정을 활성화하면 더 나은 검색을 위해 추가 컨텍스트로 청킹을 향상시킬 수 있습니다. 활성화하면 청크 풍부화 및 콘텐츠 분석을 위해 LLM 모델을 선택할 수 있습니다.
- 청크 크기: 각 청크의 최대 크기를 토큰/문자로 지정합니다. 기본값은
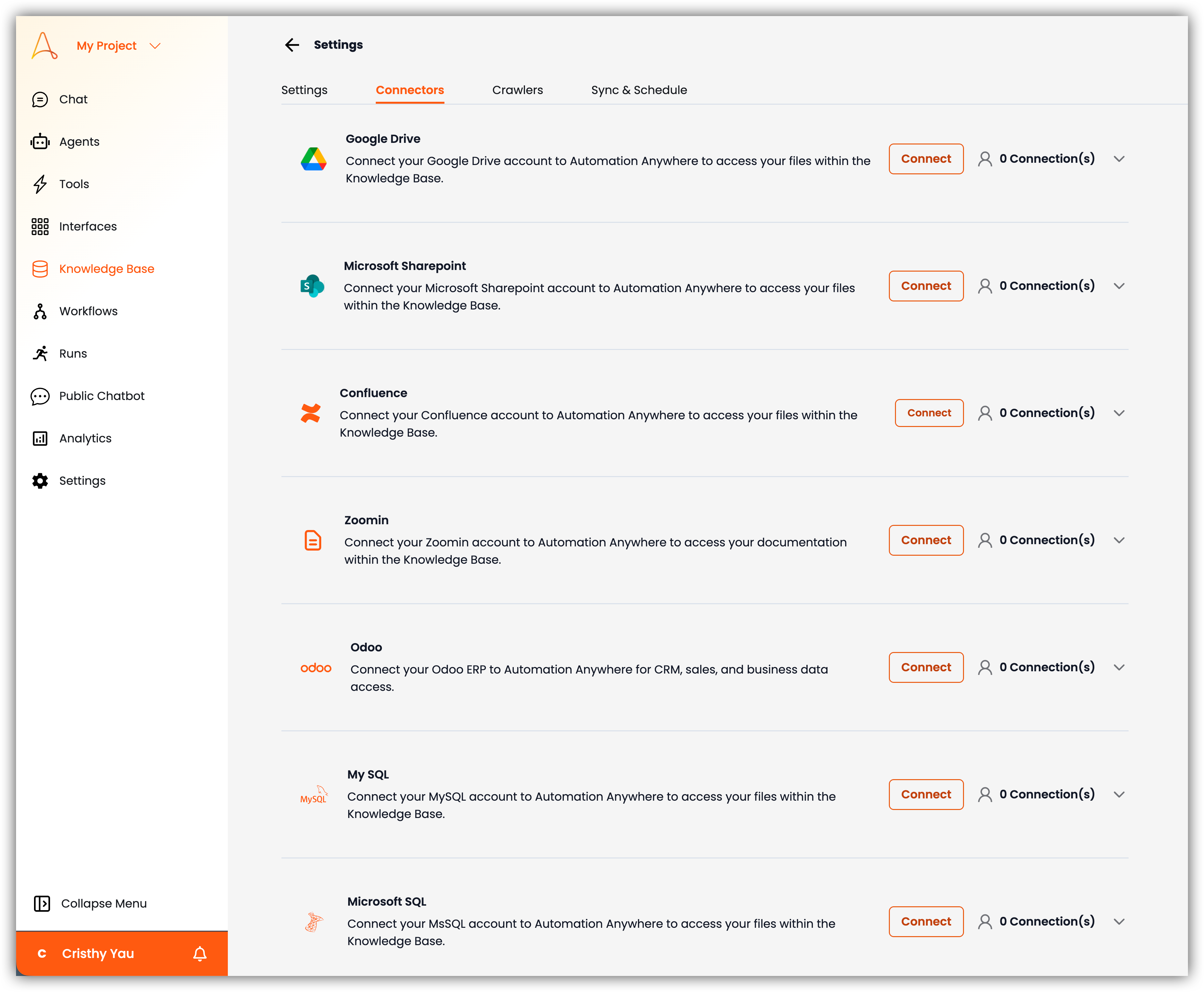
- 커넥터: Google Drive, SharePoint, Confluence, Zoomin과 같은 서드파티 통합을 관리합니다.
- 크롤러: 웹사이트 도메인 URL에서 데이터를 가져오기 위해 새 웹 크롤러를 만듭니다. 크롤러가 웹사이트 내에서 발견할 수 있는 모든 페이지는 자동으로 크롤링되어 지식 기반에 추가됩니다. 새로 추가된 페이지에서 최신 정보를 추가하는 자동 크롤링 예약도 설정할 수 있습니다.
- 동기화 및 예약: 지식 기반의 동기화 및 예약 설정을 관리합니다. 여기서 서드파티 통합의 동기화 예약을 보고 관리할 수 있으며, 수동 동기화를 실행하여 최신 데이터를 가져올 수 있습니다.
- 청킹 전략: 문서가 처리를 위해 청크로 분할되는 방법을 구성합니다. 다음 옵션 중에서 선택합니다:
템플릿
템플릿
템플릿은 Q&A 쌍, 응답 템플릿 및 예시로, 전체 문서에서 답변을 검색하는 대신 이 템플릿을 사용하여 더 정확하고 맥락적으로 관련된 응답을 생성하도록 AI 에이전트를 안내하는 데 사용할 수 있습니다. 빠르고 정확한 답변을 제공할 수 있습니다. 특정 사용 사례에 맞게 템플릿을 만들고, 관리하고, 정리할 수 있습니다. FAQ 스타일 템플릿의 경우 AI 에이전트에 추가 컨텍스트를 제공하기 위해 지식 기반에서 파일을 연결할 수도 있습니다.
템플릿 섹션의 주요 기능을 살펴보겠습니다:
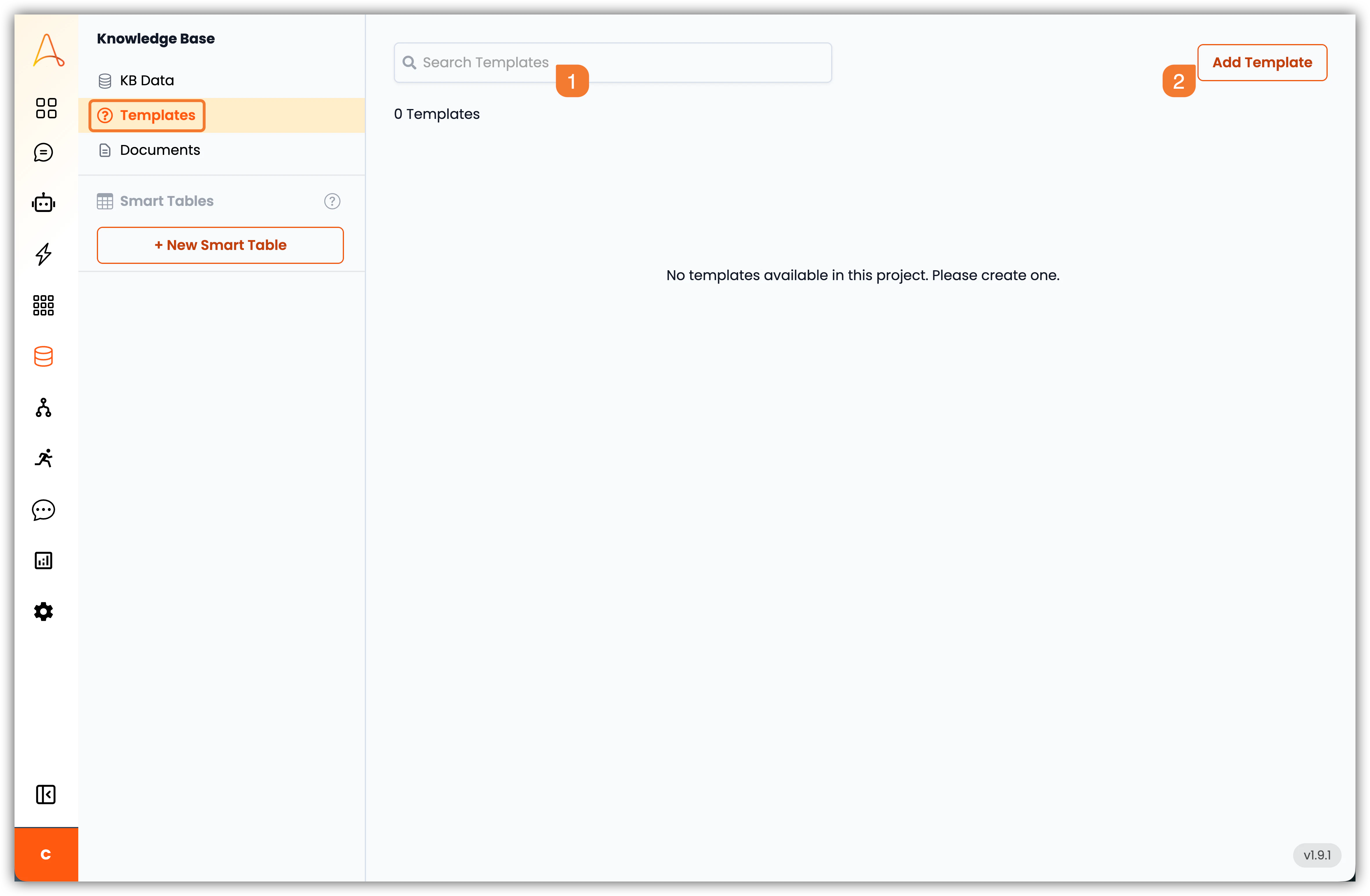
- 검색 표시줄: 검색 표시줄을 사용하여 지식 기반 내에서 특정 템플릿을 빠르게 찾을 수 있습니다.
- 템플릿 추가: 이 버튼을 클릭하여 새 템플릿을 만듭니다. 유형(FAQ, 템플릿 또는 예시), 내용을 정의하고 추가 컨텍스트를 위해 지식 기반에서 파일을 연결할 수 있습니다.
문서
문서
문서 섹션에서는 업로드할 필요 없이 지식 기반 내에서 직접 새 텍스트 기반 파일을 만들 수 있습니다. 이 기능은 매끄러운 문서화, 편집 및 AI 기반 지식 검색과의 통합을 가능하게 합니다.
문서 섹션의 주요 기능을 살펴보겠습니다:
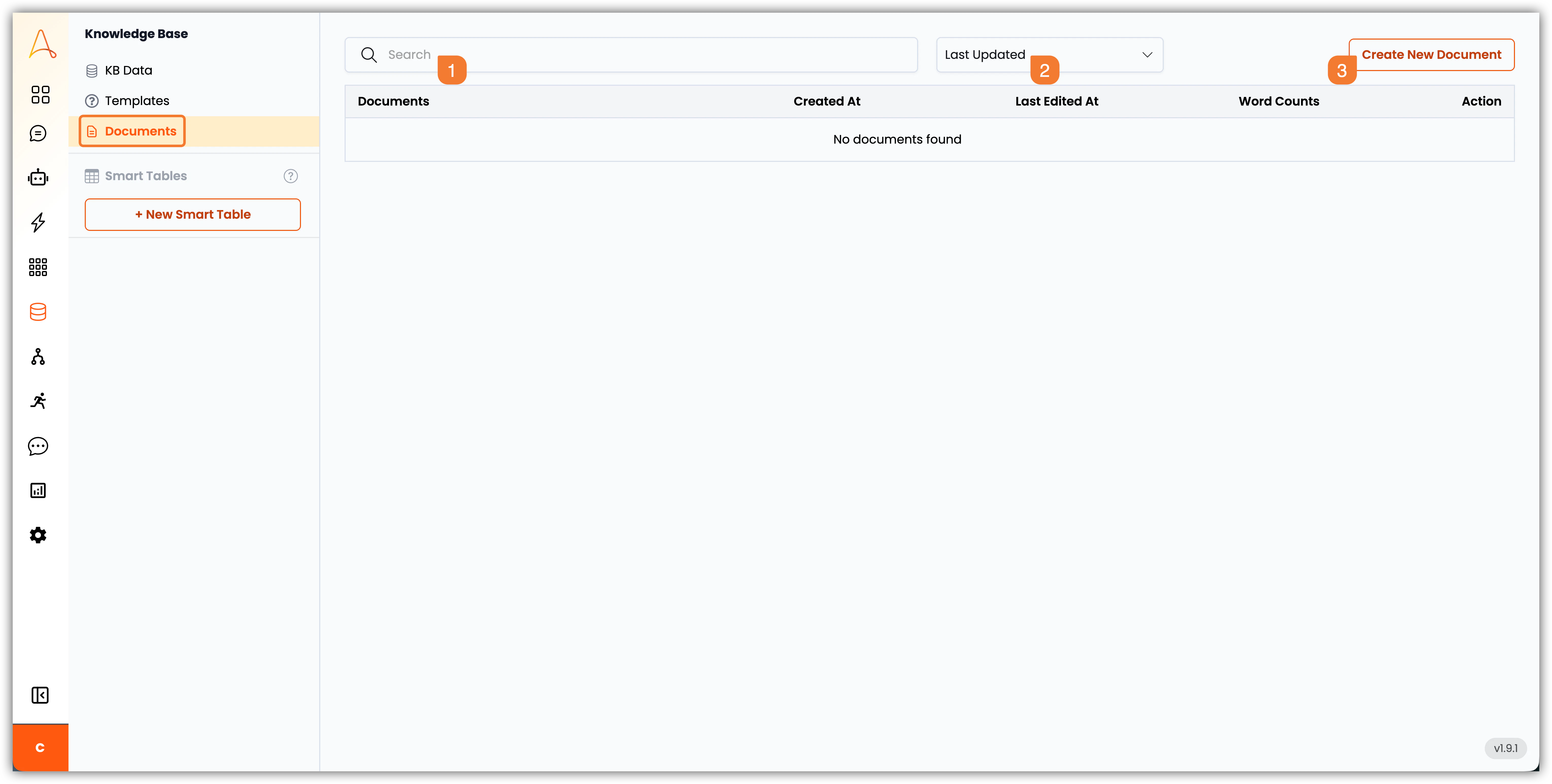
- 검색 표시줄: 검색 표시줄을 사용하여 특정 문서를 빠르게 찾을 수 있습니다.
- 필터: 필터를 사용하여 다음 기준으로 문서를 봅니다:
최종 업데이트,생성 날짜,제목또는단어 수. - 새 문서 만들기: 이 버튼을 클릭하여 새 문서를 만듭니다.
스마트 테이블
스마트 테이블
스마트 테이블
스마트 테이블은 PDF, DOCX 및 스캔된 문서와 같은 비구조화된 소스에서 구조화된 데이터를 저장, 정리 및 추출하도록 구축된 동적 스프레드시트 스타일 테이블입니다. 단순한 테이블 이상입니다. 문서를 업로드하고, AI를 사용하여 주요 데이터를 추출하며, 의사 결정과 자동화를 매끄럽게 만드는 방식으로 데이터를 구조화할 수 있는 지능형 워크스페이스입니다. 활용도는 무한합니다!스마트 테이블 섹션의 주요 기능을 살펴보겠습니다:
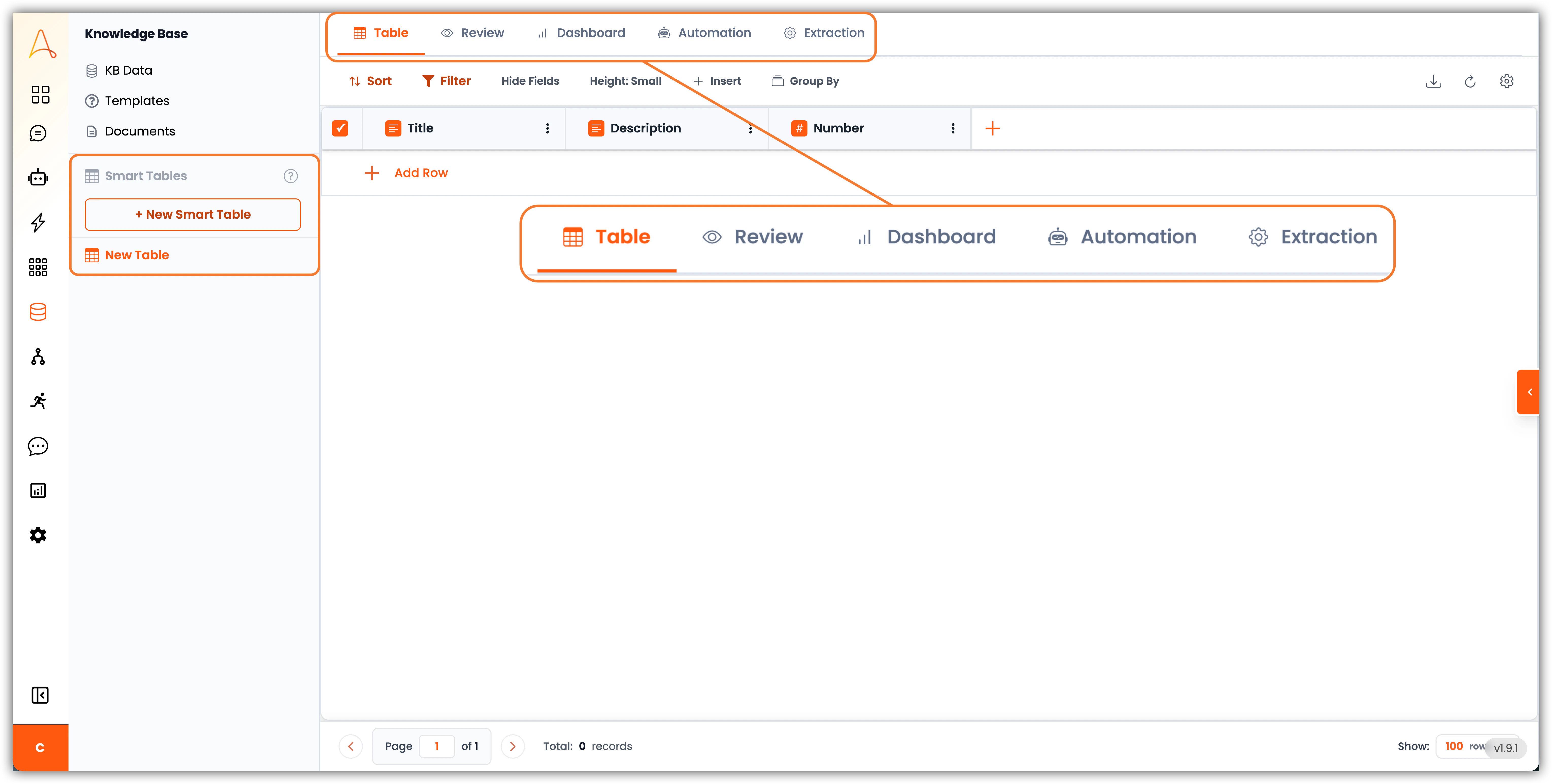
- 탐색 – 왼쪽에 + 새 스마트 테이블 버튼과 이전에 만든 스마트 테이블 목록이 있습니다. 버튼 위에 마우스를 올리면 새 테이블을 만들기 위한 몇 가지 옵션이 표시됩니다:
- 빈 테이블 만들기
- 파일에서 가져오기
- 템플릿에서 만들기
- 테이블 탭 – 스마트 테이블의 모든 데이터를 스프레드시트 스타일 보기로 볼 수 있는 메인 페이지입니다. 여기서 모든 행과 필드를 명확하게 볼 수 있습니다. 데이터를 직접 정리하고 편집하기에 적합합니다.
- 검토 탭 – 이 보기는 승인 전에 추출된 데이터를 검증하거나 검토할 때 유용한 사람-in-the-loop 프로세스를 위해 설계되었습니다.
- 대시보드 – 여기서 차트, 개수 및 통계로 데이터를 시각화하는 대시보드를 만들 수 있습니다.
- 자동화 – 스마트 테이블에서는 값을 계산하는 작업이 포함된 열을 만들거나 AI 에이전트 또는 LLM을 사용하여 테이블의 정보를 기반으로 평가를 수행하거나 정보를 찾을 수 있습니다. 자동화 탭은 이러한 열의 자동 계산을 위한 열 실행 순서 및 기록 추적을 구성하는 곳입니다.
- 추출 – 이 탭은 AI 기반 문서 추출의 핵심입니다. 여기서 어떤 데이터를 가져올지 매핑하고, 테이블 열에 매핑하며, 데이터가 추출되는 방법을 구성할 수 있습니다.
문서 보기 인터페이스
지식 기반에서 문서를 클릭하면 문서 보기 인터페이스가 열립니다. 여기서 문서의 메타데이터와 관련 정보를 읽고 관리할 수 있습니다. 인터페이스는 문서 콘텐츠 영역과 메타데이터 사이드바의 두 가지 주요 섹션으로 나뉩니다.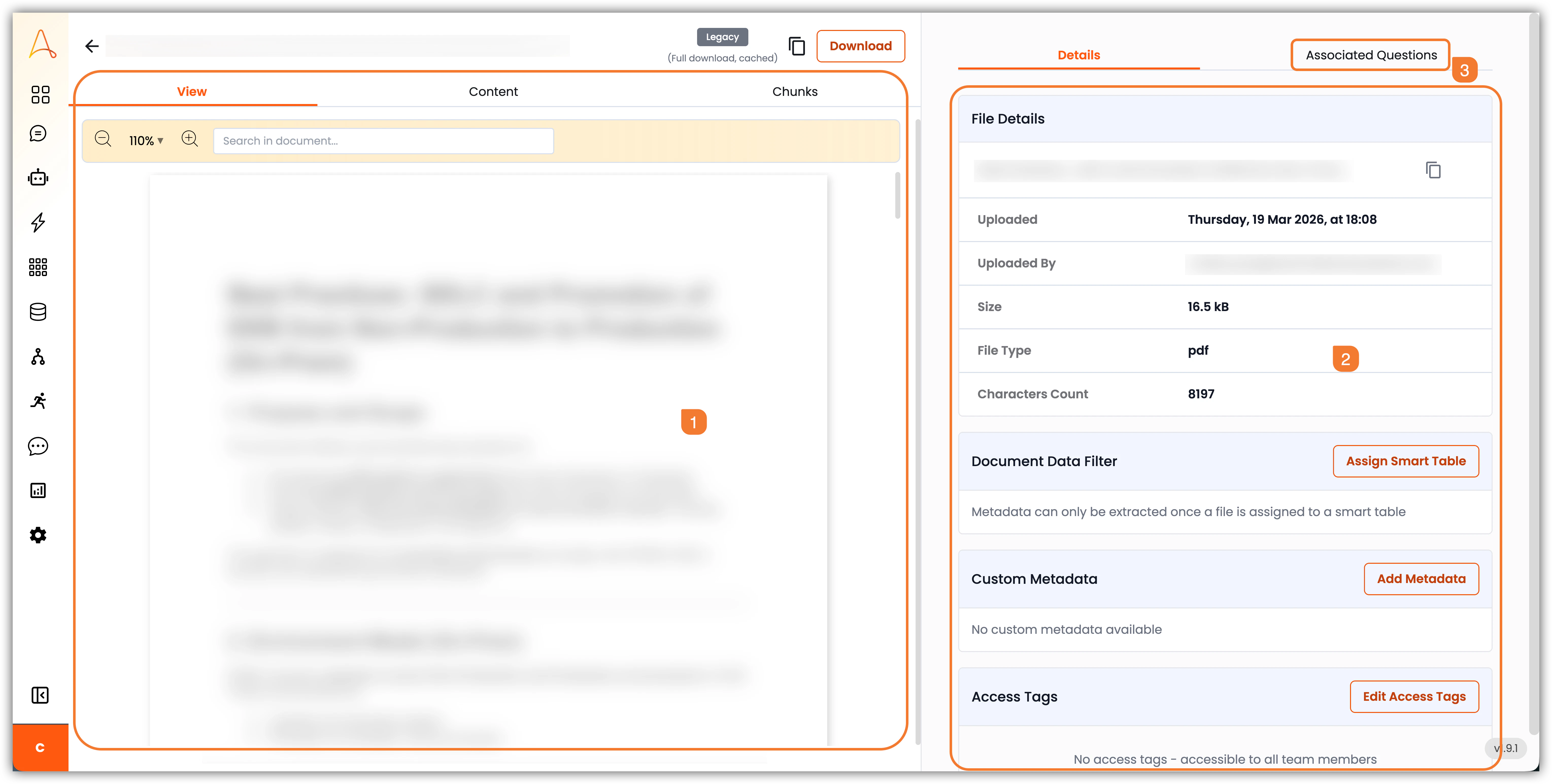
- 문서 콘텐츠 영역: 문서의 주요 내용이 표시되는 곳입니다. 화면 상단에 파일 이름을 복사하거나 파일을 다운로드하는 버튼이 있습니다. 이 영역에는 세 가지 탭이 있습니다:
a. 보기: 업로드된 대로 파일의 내용을 표시합니다.
b. 콘텐츠: 파일에서 추출된 텍스트 내용을 표시합니다. 이는 AI 에이전트가 검색과 질문 답변에 사용할 콘텐츠입니다.
c. 청크: 지식 기반 설정에서 구성된 청킹 전략을 기반으로 만들어진 개별 텍스트 청크를 표시합니다. 각 청크는 AI 에이전트가 독립적으로 검색할 수 있는 문서의 더 작은 세그먼트입니다. - 세부 정보 사이드바: 이 사이드바는 파일 정보, 문서 데이터 필터, 사용자 지정 메타데이터, 접근 태그를 포함한 추가 정보와 옵션을 제공합니다:
d. 파일 세부 정보: 파일 이름, 업로드 날짜, 업로드 사용자, 파일 크기, 파일 유형, 문자 수 등 파일에 대한 정보를 표시합니다.
e. 문서 데이터 필터: 스마트 테이블의 스키마를 기반으로 구조화된 데이터 추출을 위해 문서에 스마트 테이블을 할당할 수 있습니다.
f. 사용자 지정 메타데이터: 저자 이름, 버전, 페이지, 해상도, 치수, 콘텐츠 작성자, 키워드 등 문서 분류 및 AI 기반 검색을 향상시키기 위해 문서에 사용자 지정 메타데이터 필드를 추가할 수 있습니다.
g. 접근 태그: 문서에 접근 태그를 추가하여 문서를 보거나 상호작용할 수 있는 사람을 제어할 수 있습니다. 새 태그는 슈퍼 관리자 대시보드에서 만들 수 있습니다. - 연관 질문: 연관 질문 탭을 사용하면 문서의 콘텐츠로 답변할 수 있는 관련 자주 묻는 질문을 추가할 수 있습니다. 이를 통해 문서의 콘텐츠를 기반으로 정확하고 관련성 있는 답변을 제공하는 AI 에이전트의 능력을 향상시킬 수 있습니다.
문제 해결
이 섹션은 사용자가 지식 기반에서 자주 직면하는 문제와 식별 및 해결을 위한 1단계(L1) 진단 단계를 다룹니다.지식 기반 업데이트 안 됨
증상:- 새로 업로드된 문서가 검색 결과에 나타나지 않음
- 기존 문서의 변경 사항이 AI 응답에 반영되지 않음
- 커넥터 데이터가 동기화되지 않음
-
동기화 상태 확인
- 설정 > 동기화 및 예약로 이동
- 자동 동기화가 활성화되어 있는지 확인하고 마지막 동기화 타임스탬프 확인
- 오류 메시지 또는 실패한 동기화 시도 확인
-
문서 처리 확인
- 지식 기반에서 문서를 엽니다
- 콘텐츠 탭을 확인하여 텍스트가 올바르게 추출되었는지 확인
- 청크 탭을 검토하여 청킹이 완료되었는지 확인
- 문서 메타데이터에서 처리 오류 확인
-
임베딩 모델 일관성 확인
- 설정 > 설정 탭으로 이동
- 인덱싱에 사용된 임베딩 모델이 쿼리에 사용된 것과 일치하는지 확인
- 문서가 인덱싱된 후 임베딩 모델이 변경되지 않았는지 확인
-
수동 동기화
- 문서 또는 폴더를 마우스 오른쪽 버튼으로 클릭
- 동기화를 선택하여 재처리를 수동으로 트리거
- 동기화가 완료될 때까지 기다린 후 문제가 해결되었는지 확인
-
커넥터 상태 검토
- 커넥터(Google Drive, SharePoint 등)를 사용하는 경우 설정 > 커넥터에서 커넥터 상태 확인
- 인증이 여전히 유효한지 확인
- 연결 오류 또는 속도 제한 경고 확인
검색 불일치
증상:- 검색 쿼리가 관련 문서를 반환하지 않음
- AI 에이전트가 지식 기반에 존재하는 정보를 찾지 못함
- 잘못되거나 관련 없는 검색 결과
-
문서 내용 확인
- 문서를 열고 콘텐츠 탭 확인
- 텍스트 내용이 정확하고 완전한지 확인
- 문서가 올바르게 처리되었는지 확인(추출 오류 없음)
-
청킹 구성 확인
- 설정 > 설정 > 청킹 전략 검토
- 청크 크기와 겹침 설정이 콘텐츠에 적절한지 확인
- 청크 크기가 너무 큰지(특정 정보를 놓칠 수 있음) 또는 너무 작은지(컨텍스트를 잃을 수 있음) 고려
-
임베딩 모델 검토
- 사용 중인 임베딩 모델이 콘텐츠 유형에 적합한지 확인
- 모델이 문서의 언어를 지원하는지 확인
- 인덱싱과 쿼리 간 임베딩 모델 일관성 확인
-
검색 쿼리 테스트
- 동일한 쿼리의 다른 문구를 시도
- 문서 콘텐츠에 나타나는 키워드 사용
- 정확한 문구 대신 키워드로 검색이 더 잘 작동하는지 확인
-
문서 메타데이터 확인
- 문서에 할당된 사용자 지정 메타데이터 및 태그 검토
- 문서가 올바르게 분류되고 태그가 지정되었는지 확인
- 접근 태그가 가시성을 제한하지 않는지 확인
-
청크 검토
- 문서의 청크 탭을 엽니다
- 청크에 예상된 정보가 포함되어 있는지 확인
- 관련 정보가 여러 청크에 걸쳐 분할되어 있는지 확인
데이터가 보이지 않음
증상:- 문서가 지식 기반 목록에 나타나지 않음
- 업로드된 파일이 나타나지 않음
- 동기화 후 커넥터 데이터가 보이지 않음
-
파일 필터 확인
- KB 데이터 페이지 상단의 파일 유형 필터 검토
- 필터가 문서 유형을 제외하지 않는지 확인
- 모든 필터를 지우고 모든 문서가 표시되는지 확인
-
업로드 상태 확인
- 업로드가 성공적으로 완료되었는지 확인
- 업로드 중 오류 메시지 확인
- 파일 크기와 형식이 지원되는지 확인
-
폴더 구조 검토
- 문서가 하위 폴더에 있는지 확인
- 폴더를 탐색하여 문서를 찾습니다
- 검색 표시줄을 사용하여 이름으로 문서 찾기
-
접근 권한 확인
- 문서를 볼 수 있는 접근 권한이 있는지 확인
- 접근 태그가 가시성을 제한하지 않는지 확인
- 올바른 계정으로 로그인되어 있는지 확인
-
처리 상태 검토
- 문서가 업로드 후 아직 처리 중일 수 있음
- 파일 목록에서 문서 상태 확인
- 처리가 진행 중이면 몇 분 기다린 후 새로고침
-
커넥터 구성 확인
- 커넥터를 사용하는 경우 커넥터 설정 확인
- 동기화할 올바른 폴더/파일이 선택되어 있는지 확인
- 동기화 예약이 올바르게 구성되어 있는지 확인
추가 문제 해결 팁
- 브라우저 캐시 지우기: 때때로 UI 문제는 브라우저 캐시를 지우면 해결될 수 있습니다
- 브라우저 콘솔 확인: 브라우저 개발자 도구(F12)를 열고 JavaScript 오류 확인
- 네트워크 연결 확인: 동기화 작업을 위해 안정적인 인터넷 연결 확인
- 시스템 로그 검토: EKB 시스템 로그에서 백엔드 오류 확인(관리자 접근 권한 필요)
- 지원팀에 문의: L1 진단 후에도 문제가 지속되면 support@automationanywhere.com으로 문의하세요:
- 문제 설명
- 진단을 위해 수행한 단계
- 오류 메시지 스크린샷
- 영향을 받는 문서/파일 이름