RAG技術の解説
ファイルをプラットフォームにアップロードすると、高度なパイプラインを通過して処理されます。まず、テキスト抽出によりPDF、DOCX、その他のフォーマットから生テキストを取得し、必要に応じてスキャン画像にOCRを適用します。次に、チャンキングによりテキストをより小さな管理可能なセグメントに分割します。次に、埋め込みにより、各チャンクを埋め込みモデルを使用してベクトル(意味を表す数値のリスト)に変換します。最後に、ストレージによりこれらのベクトルをベクトルデータベースに保存します。エージェントが検索する場合、クエリも埋め込まれ、データベースがクエリに最も近い数学的近接性(意味)を持つチャンクを検索します。設定パネル
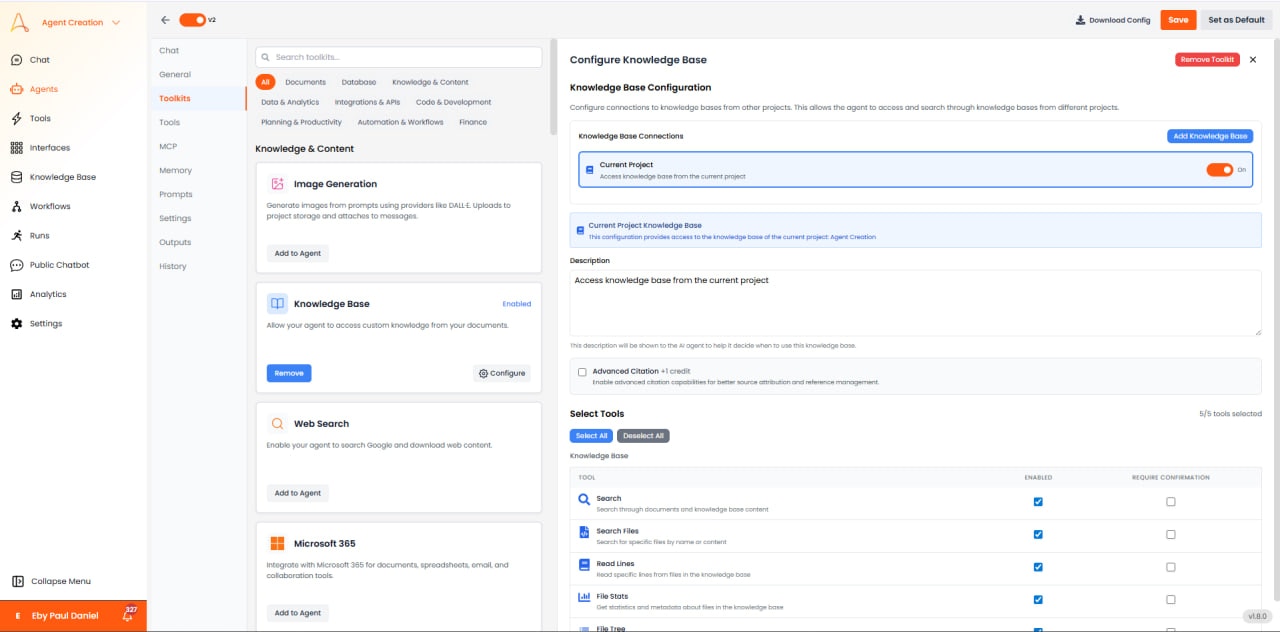
- Current Project Knowledge Base: デフォルトで有効になっており、現在のワークスペース内のファイルへのアクセスを許可します。
- Cross-Project Access: 他のプロジェクトのKBへのリンクを許可します(例:一元的な「会社方針」プロジェクト)。
- Description: KBの内容を説明するメタデータは、エージェントがこのツールを使用するタイミングを判断するのに役立ちます。
- Advanced Citation(+1クレジット): 有効にすると、ソーステキストにリンクした厳密なインライン引用を提供します。
利用可能なサブツール
- Search Tool: セマンティック検索のためのプライマリツールです。キーワードが完全に一致しなくても関連情報を見つかります。
- Search Files Tool: 内容ではなくファイル名で特定のファイルを見つけるためのメタデータ検索です。
- Read Lines Tool: 特定のファイルから生テキストを抽出します。エージェントが章やセクション全体を詳しく読む必要がある場合に便利です。
- File Stats Tool: ファイルサイズ、作成者、作成日、ページ数などのメタデータを返します。
- File Tree Tool: ディレクトリ構造を一覧表示します。新しいKBを探索し、ファイルの整理方法を理解するためにエージェントに必須です。
実装例
- 履歴書スクリーニング: エージェントがアップロードされたすべてのPDFで「Python経験」を検索し、異なる履歴書から関連チャンクを取得し、上位の候補者を要約します。
- 方針Q&A: ユーザーが「タクシーの経費精算はできますか?」と尋ねます。エージェントは「Travel Policy」を検索し、陸上交通セクションを見つけ、「はい、クライアントの出張の場合、セクション4.2に従います」と回答します。
- テクニカルサポート: エージェントが技術マニュアルを検索し、エラーコードとトラブルシューティング手順を見つけます。