> ## Documentation Index
> Fetch the complete documentation index at: https://ai-kb.automationanywhere.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Aperçu
> Référentiel centralisé pour vos agents IA
La **Base de connaissances** EKB est le référentiel centralisé où vous pouvez télécharger, stocker et rechercher des informations à partir de fichiers et de liens. La Base de connaissances prend en charge la récupération d'informations via des téléchargements de fichiers, des analyses web et des intégrations avec des applications tierces telles que Google Drive, SharePoint, Confluence, Zoomin, et directement dans votre base de données avec MySQL, Microsoft SQL, Oracle et SQL générique.
# Navigation
La Base de connaissances est accessible depuis la barre latérale gauche en cliquant sur **Base de connaissances**.
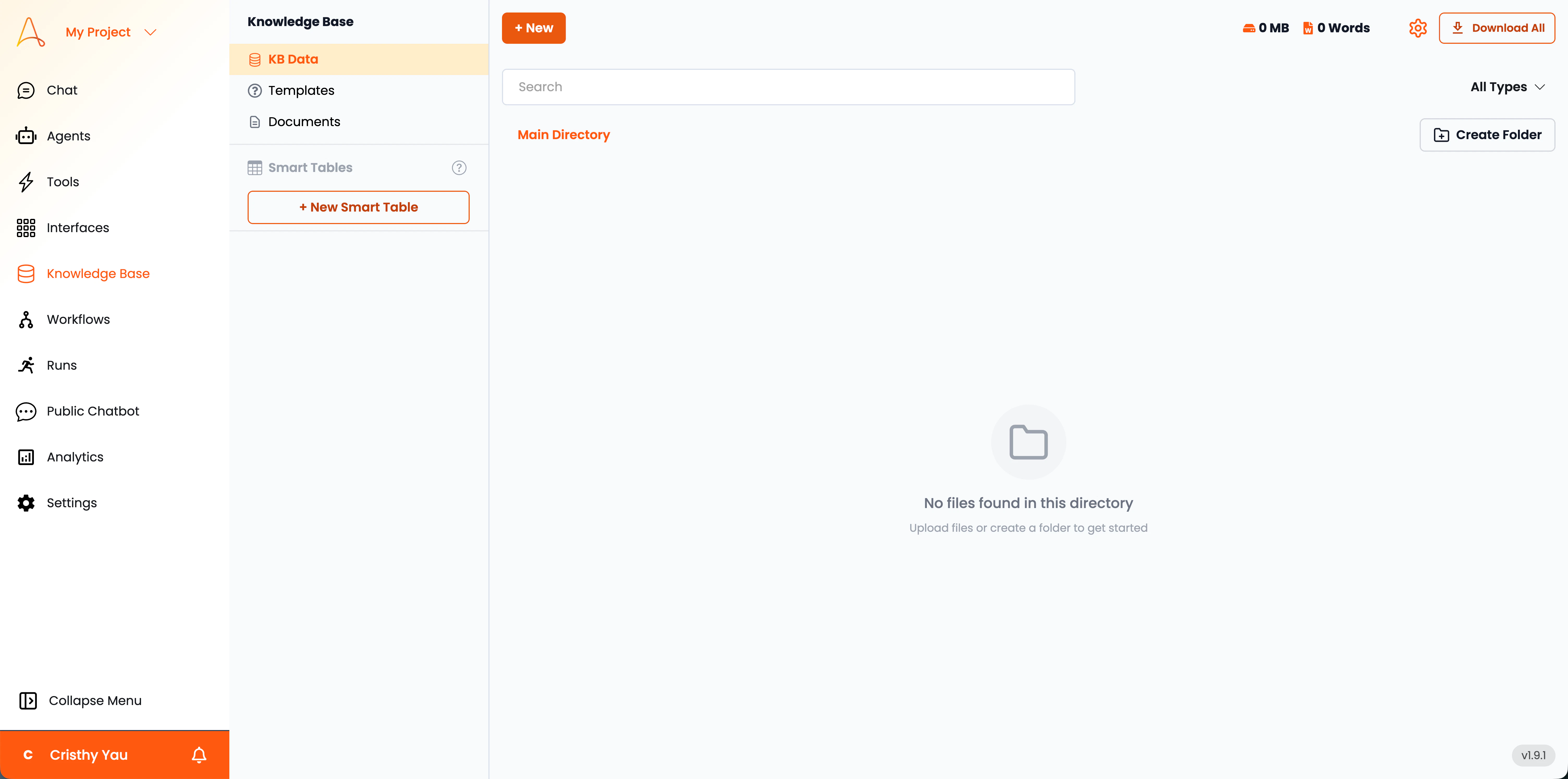 La Base de connaissances est organisée en quatre sections principales. Naviguez dans les accordéons suivants pour en savoir plus sur chaque section.
Les **Données KB** agissent comme le référentiel principal où toutes les informations récupérées sont stockées. Vous pouvez consulter, gérer et organiser vos données de base de connaissances ici. Cette section comprend les documents téléchargés, les analyses web et les données récupérées à partir d'intégrations tierces.
Explorons les fonctionnalités clés de la section Données KB :
* **Répertoire principal** : Le répertoire principal affiche toutes les données de la base de connaissances dans un format structuré. Vous pouvez voir la liste des documents, leurs types et autres détails pertinents.
La Base de connaissances est organisée en quatre sections principales. Naviguez dans les accordéons suivants pour en savoir plus sur chaque section.
Les **Données KB** agissent comme le référentiel principal où toutes les informations récupérées sont stockées. Vous pouvez consulter, gérer et organiser vos données de base de connaissances ici. Cette section comprend les documents téléchargés, les analyses web et les données récupérées à partir d'intégrations tierces.
Explorons les fonctionnalités clés de la section Données KB :
* **Répertoire principal** : Le répertoire principal affiche toutes les données de la base de connaissances dans un format structuré. Vous pouvez voir la liste des documents, leurs types et autres détails pertinents.
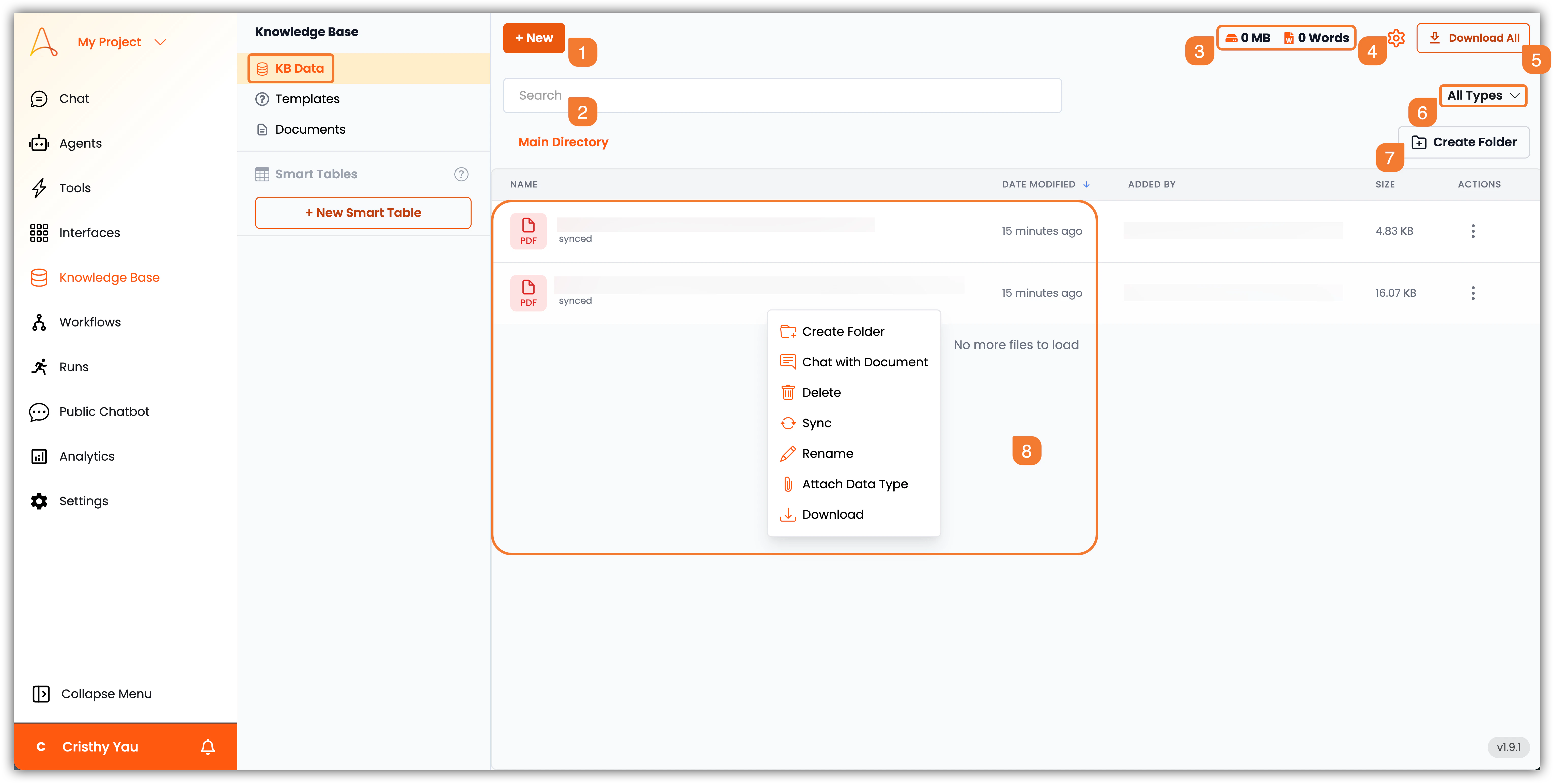 1. **+Nouveau** : Cliquez sur ce bouton pour ajouter de nouvelles données à la base de connaissances. Vous pouvez télécharger des fichiers ou des dossiers, lancer des analyses web, télécharger des données depuis une URL ou créer un document.
2. **Barre de recherche** : Utilisez la barre de recherche pour trouver rapidement des documents ou des informations spécifiques dans votre base de connaissances.
3. **Stockage et nombre de mots** : Cette section affiche le stockage total utilisé et le nombre de mots de vos données de base de connaissances.
4. **Paramètres** : Cliquez sur l'icône des paramètres pour configurer comment votre base de connaissances traite et intègre les documents, ce qui affecte la façon dont le contenu est fragmenté, intégré et récupéré. Vous pouvez également gérer les Connecteurs (c'est-à-dire les intégrations tierces), les analyseurs et la synchronisation et la planification de la Base de connaissances avec les applications tierces connectées à partir de cette section.
5. **Télécharger tout** : Cliquez sur ce bouton pour télécharger toutes les données de la base de connaissances sous forme de fichier ZIP.
6. **Filtre de fichier** : Utilisez le filtre de fichier pour afficher les documents par type : PDF, Word, Excel, PowerPoint, Texte, CSV, etc.
7. **Créer un dossier** : Cliquez sur ce bouton pour créer un nouveau dossier et organiser vos données de base de connaissances.
8. **Liste des fichiers** : Cette section affiche la liste des fichiers et dossiers dans votre base de connaissances. Vous pouvez cliquer sur un fichier pour afficher son contenu et ses métadonnées, et vous pouvez faire un clic droit sur un fichier ou un dossier pour accéder à des options supplémentaires telles que :
* **Créer un dossier** : Créez un nouveau dossier dans le répertoire actuel.
* **Discuter avec le document** : Ouvrez une interface de chat pour interagir avec le contenu du document sélectionné.
* **Supprimer** : Supprimez le fichier ou le dossier sélectionné de la base de connaissances.
* **Synchroniser** : Synchronisez manuellement le fichier ou le dossier sélectionné pour retraiter le contenu du fichier.
* **Joindre le type de données** : Cette option vous permet de joindre un schéma de données au fichier sélectionné, permettant des capacités d'extraction et de requête de données structurées.
* **Télécharger** : Téléchargez le fichier sélectionné sur votre appareil local.
* **Paramètres de base de connaissances** : Voici les paramètres clés que vous pouvez configurer :
1. **+Nouveau** : Cliquez sur ce bouton pour ajouter de nouvelles données à la base de connaissances. Vous pouvez télécharger des fichiers ou des dossiers, lancer des analyses web, télécharger des données depuis une URL ou créer un document.
2. **Barre de recherche** : Utilisez la barre de recherche pour trouver rapidement des documents ou des informations spécifiques dans votre base de connaissances.
3. **Stockage et nombre de mots** : Cette section affiche le stockage total utilisé et le nombre de mots de vos données de base de connaissances.
4. **Paramètres** : Cliquez sur l'icône des paramètres pour configurer comment votre base de connaissances traite et intègre les documents, ce qui affecte la façon dont le contenu est fragmenté, intégré et récupéré. Vous pouvez également gérer les Connecteurs (c'est-à-dire les intégrations tierces), les analyseurs et la synchronisation et la planification de la Base de connaissances avec les applications tierces connectées à partir de cette section.
5. **Télécharger tout** : Cliquez sur ce bouton pour télécharger toutes les données de la base de connaissances sous forme de fichier ZIP.
6. **Filtre de fichier** : Utilisez le filtre de fichier pour afficher les documents par type : PDF, Word, Excel, PowerPoint, Texte, CSV, etc.
7. **Créer un dossier** : Cliquez sur ce bouton pour créer un nouveau dossier et organiser vos données de base de connaissances.
8. **Liste des fichiers** : Cette section affiche la liste des fichiers et dossiers dans votre base de connaissances. Vous pouvez cliquer sur un fichier pour afficher son contenu et ses métadonnées, et vous pouvez faire un clic droit sur un fichier ou un dossier pour accéder à des options supplémentaires telles que :
* **Créer un dossier** : Créez un nouveau dossier dans le répertoire actuel.
* **Discuter avec le document** : Ouvrez une interface de chat pour interagir avec le contenu du document sélectionné.
* **Supprimer** : Supprimez le fichier ou le dossier sélectionné de la base de connaissances.
* **Synchroniser** : Synchronisez manuellement le fichier ou le dossier sélectionné pour retraiter le contenu du fichier.
* **Joindre le type de données** : Cette option vous permet de joindre un schéma de données au fichier sélectionné, permettant des capacités d'extraction et de requête de données structurées.
* **Télécharger** : Téléchargez le fichier sélectionné sur votre appareil local.
* **Paramètres de base de connaissances** : Voici les paramètres clés que vous pouvez configurer :
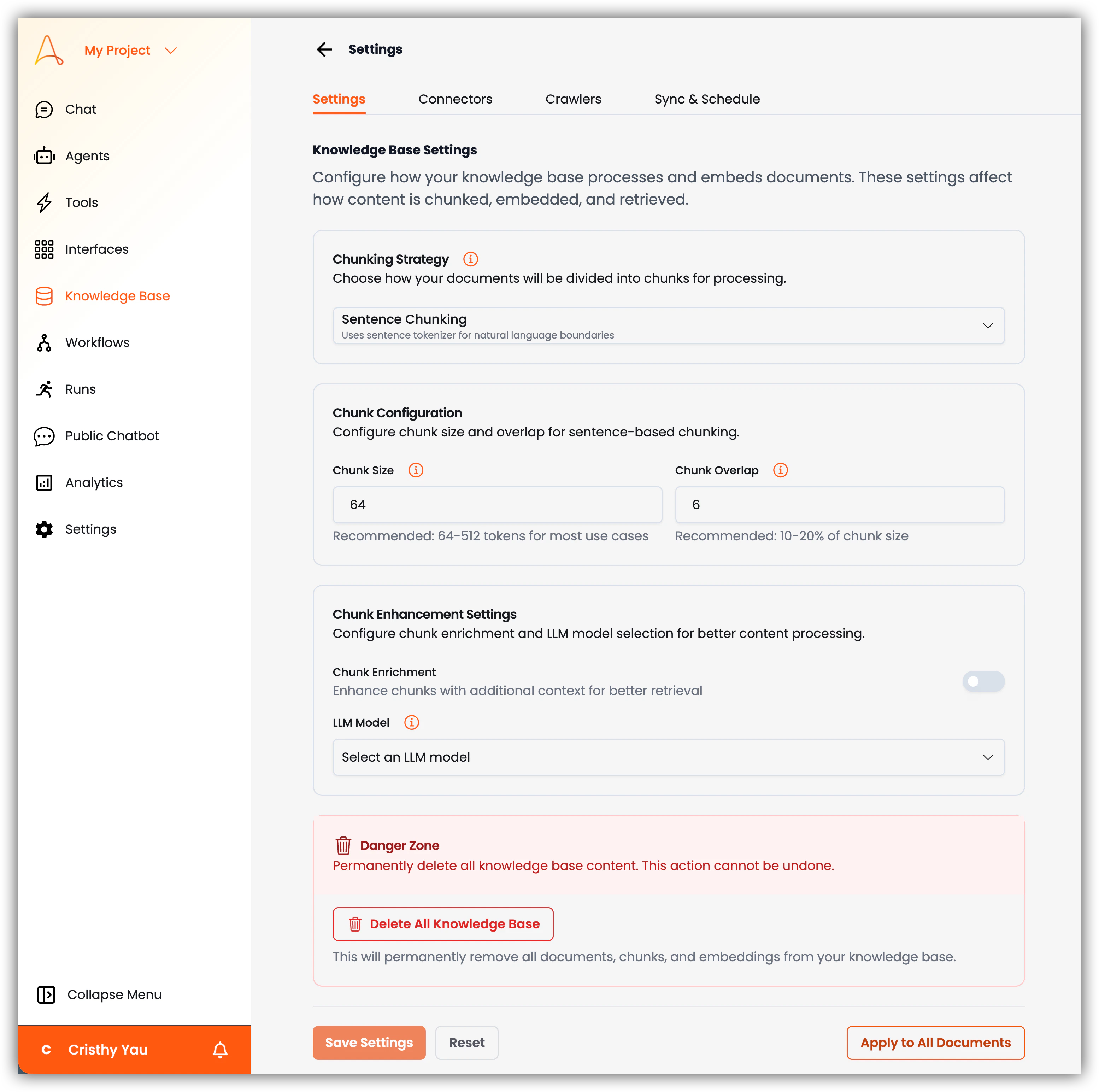 1. **Stratégie de fragmentation** : Configurez la façon dont les documents seront divisés en fragments pour le traitement. Choisissez parmi ces options :
* **Fragmentation par phrase** : Divise le texte en fragments basés sur les limites des phrases, en s'assurant que chaque fragment contient des phrases complètes. Cette option utilise le tokeniseur de phrases pour les limites du langage naturel.
* **Fragmentation sémantique** : Divise le texte en fragments sémantiquement significatifs, qui peuvent ne pas s'aligner avec les limites des phrases. Cette option utilise le tokeniseur sémantique pour les limites du langage naturel.
* **Configuration de fragmentation** : Cette configuration apparaît lorsque vous sélectionnez *Fragmentation par phrase*. Ici, vous pouvez configurer la taille du fragment et le chevauchement pour la fragmentation basée sur les phrases.
* **Taille du fragment** : Spécifiez la taille maximale de chaque fragment en jetons/caractères. La valeur par défaut est `64`. La recommandation est entre `64` et `512` jetons pour la plupart des cas d'usage. Les fragments plus grands préservent le contexte mais peuvent être moins précis pour la récupération.
* **Chevauchement de fragments** : Spécifiez le nombre de mots qui se chevauchent entre les fragments consécutifs. Cela aide à maintenir le contexte au-delà des limites des fragments. La valeur par défaut est `16`. La recommandation est entre 10 et 20 % de la taille de fragment définie.
* **Paramètres d'amélioration de fragments** : Activez ce paramètre pour améliorer la fragmentation avec un contexte supplémentaire pour une meilleure récupération. Lorsqu'il est activé, vous pouvez sélectionner un modèle LLM pour l'enrichissement des fragments et l'analyse du contenu.
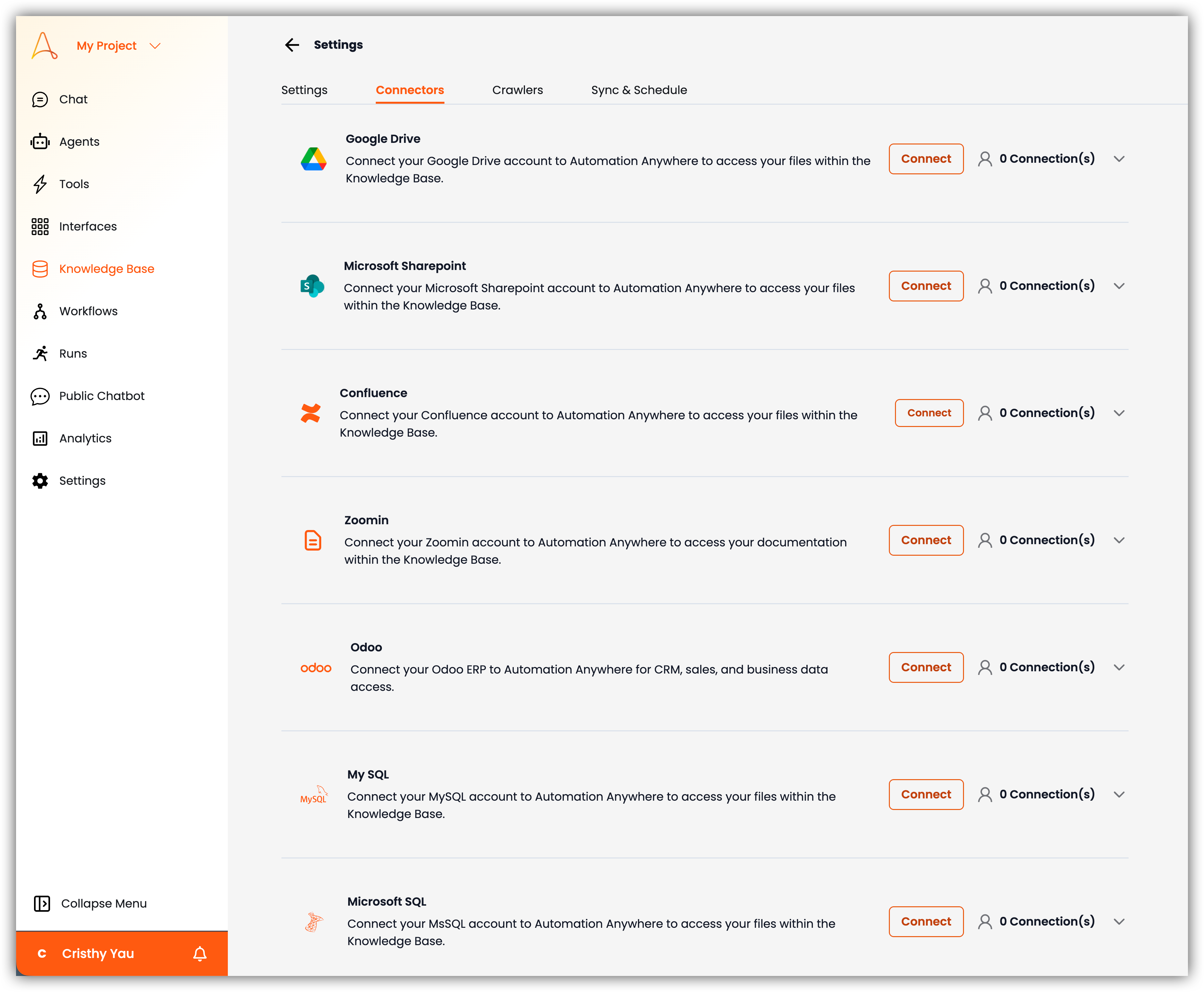
2. **Connecteurs** : Gérez les intégrations tierces telles que Google Drive, SharePoint, Confluence et Zoomin.
1. **Stratégie de fragmentation** : Configurez la façon dont les documents seront divisés en fragments pour le traitement. Choisissez parmi ces options :
* **Fragmentation par phrase** : Divise le texte en fragments basés sur les limites des phrases, en s'assurant que chaque fragment contient des phrases complètes. Cette option utilise le tokeniseur de phrases pour les limites du langage naturel.
* **Fragmentation sémantique** : Divise le texte en fragments sémantiquement significatifs, qui peuvent ne pas s'aligner avec les limites des phrases. Cette option utilise le tokeniseur sémantique pour les limites du langage naturel.
* **Configuration de fragmentation** : Cette configuration apparaît lorsque vous sélectionnez *Fragmentation par phrase*. Ici, vous pouvez configurer la taille du fragment et le chevauchement pour la fragmentation basée sur les phrases.
* **Taille du fragment** : Spécifiez la taille maximale de chaque fragment en jetons/caractères. La valeur par défaut est `64`. La recommandation est entre `64` et `512` jetons pour la plupart des cas d'usage. Les fragments plus grands préservent le contexte mais peuvent être moins précis pour la récupération.
* **Chevauchement de fragments** : Spécifiez le nombre de mots qui se chevauchent entre les fragments consécutifs. Cela aide à maintenir le contexte au-delà des limites des fragments. La valeur par défaut est `16`. La recommandation est entre 10 et 20 % de la taille de fragment définie.
* **Paramètres d'amélioration de fragments** : Activez ce paramètre pour améliorer la fragmentation avec un contexte supplémentaire pour une meilleure récupération. Lorsqu'il est activé, vous pouvez sélectionner un modèle LLM pour l'enrichissement des fragments et l'analyse du contenu.
2. **Connecteurs** : Gérez les intégrations tierces telles que Google Drive, SharePoint, Confluence et Zoomin.
 3. **Analyseurs** : Créez de nouveaux analyseurs web pour récupérer les données de l'URL du domaine de votre site Web. Toute page que l'analyseur peut découvrir sur le site Web sera automatiquement analysée et ajoutée à la Base de connaissances. Vous pouvez également définir un calendrier de synchronisation pour l'analyse automatique qui ajoute les dernières informations des pages nouvellement ajoutées.
3. **Analyseurs** : Créez de nouveaux analyseurs web pour récupérer les données de l'URL du domaine de votre site Web. Toute page que l'analyseur peut découvrir sur le site Web sera automatiquement analysée et ajoutée à la Base de connaissances. Vous pouvez également définir un calendrier de synchronisation pour l'analyse automatique qui ajoute les dernières informations des pages nouvellement ajoutées.
 4. **Synchronisation et planification** : Gérez les paramètres de synchronisation et de planification de votre Base de connaissances. Ici, vous pouvez afficher et gérer les calendriers de synchronisation de vos intégrations tierces, ainsi qu'exécuter une synchronisation manuelle pour récupérer les données les plus récentes.
4. **Synchronisation et planification** : Gérez les paramètres de synchronisation et de planification de votre Base de connaissances. Ici, vous pouvez afficher et gérer les calendriers de synchronisation de vos intégrations tierces, ainsi qu'exécuter une synchronisation manuelle pour récupérer les données les plus récentes.
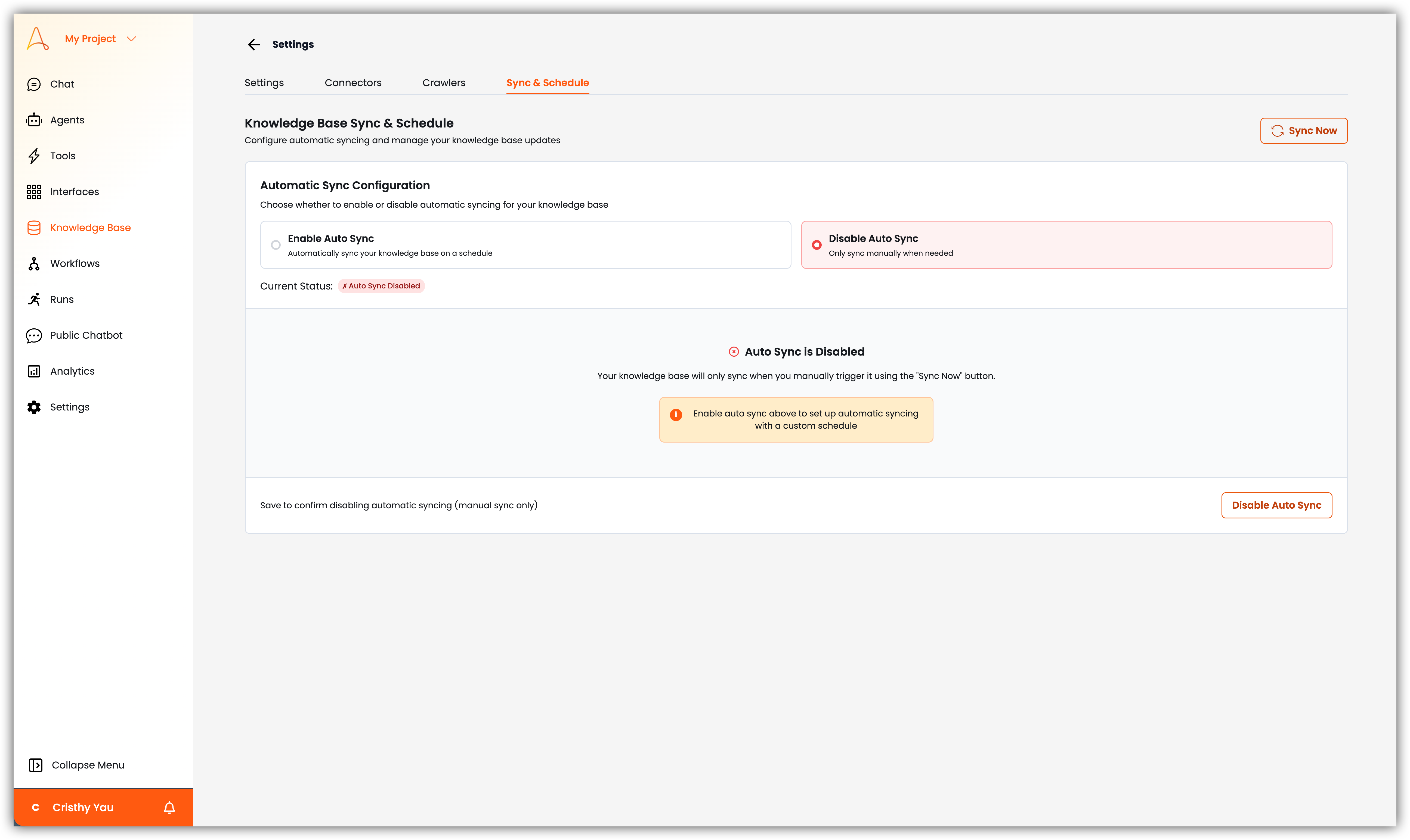 Les **Modèles** peuvent être des paires de Q/R, des modèles de réponse et des exemples que vous pouvez prédéfinir pour aider vos agents IA à générer des réponses plus précises et contextuellement pertinentes en utilisant ces modèles, plutôt que de rechercher la réponse dans des documents complets, rendant les réponses plus rapides. Vous pouvez créer, gérer et organiser des modèles en fonction de vos cas d'usage spécifiques. Pour les modèles de style FAQ, vous pouvez également associer un fichier de la Base de connaissances pour fournir un contexte supplémentaire à l'agent IA.
Explorons les fonctionnalités clés de la section Modèles :
Les **Modèles** peuvent être des paires de Q/R, des modèles de réponse et des exemples que vous pouvez prédéfinir pour aider vos agents IA à générer des réponses plus précises et contextuellement pertinentes en utilisant ces modèles, plutôt que de rechercher la réponse dans des documents complets, rendant les réponses plus rapides. Vous pouvez créer, gérer et organiser des modèles en fonction de vos cas d'usage spécifiques. Pour les modèles de style FAQ, vous pouvez également associer un fichier de la Base de connaissances pour fournir un contexte supplémentaire à l'agent IA.
Explorons les fonctionnalités clés de la section Modèles :
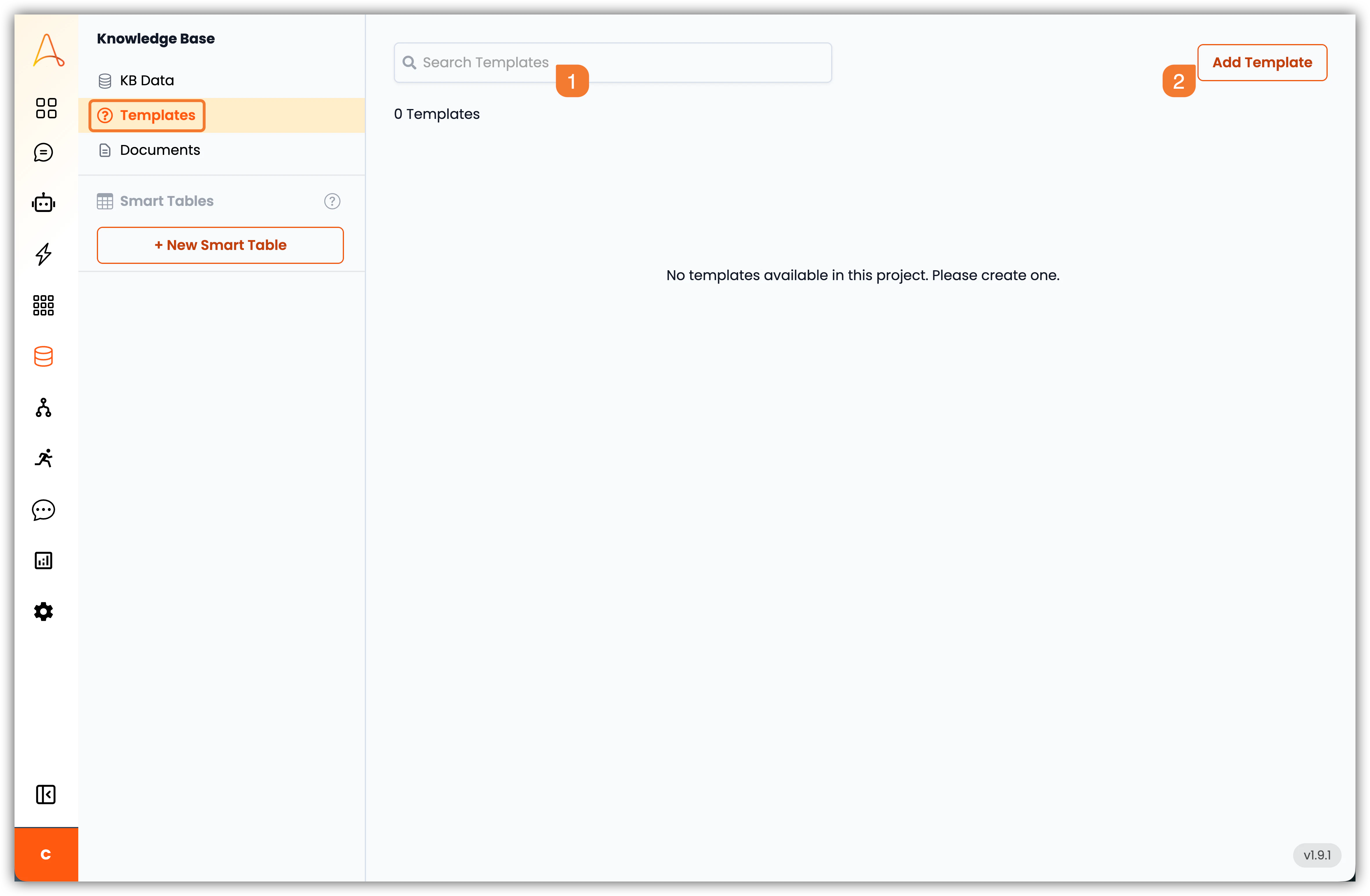 1. **Barre de recherche** : Utilisez la barre de recherche pour trouver rapidement des modèles spécifiques dans votre base de connaissances.
2. **Ajouter un modèle** : Cliquez sur ce bouton pour créer un nouveau modèle. Vous pouvez définir le type (FAQ, Modèle ou Exemple), le contenu et associer un fichier de la Base de connaissances pour un contexte supplémentaire.
Dans la section **Documents**, vous pouvez créer de nouveaux fichiers texte directement dans la Base de connaissances sans avoir besoin de les télécharger. Cette fonctionnalité permet une documentation transparente, l'édition et l'intégration avec la récupération de connaissances pilotée par l'IA.
Explorons les fonctionnalités clés de la section Documents :
1. **Barre de recherche** : Utilisez la barre de recherche pour trouver rapidement des modèles spécifiques dans votre base de connaissances.
2. **Ajouter un modèle** : Cliquez sur ce bouton pour créer un nouveau modèle. Vous pouvez définir le type (FAQ, Modèle ou Exemple), le contenu et associer un fichier de la Base de connaissances pour un contexte supplémentaire.
Dans la section **Documents**, vous pouvez créer de nouveaux fichiers texte directement dans la Base de connaissances sans avoir besoin de les télécharger. Cette fonctionnalité permet une documentation transparente, l'édition et l'intégration avec la récupération de connaissances pilotée par l'IA.
Explorons les fonctionnalités clés de la section Documents :
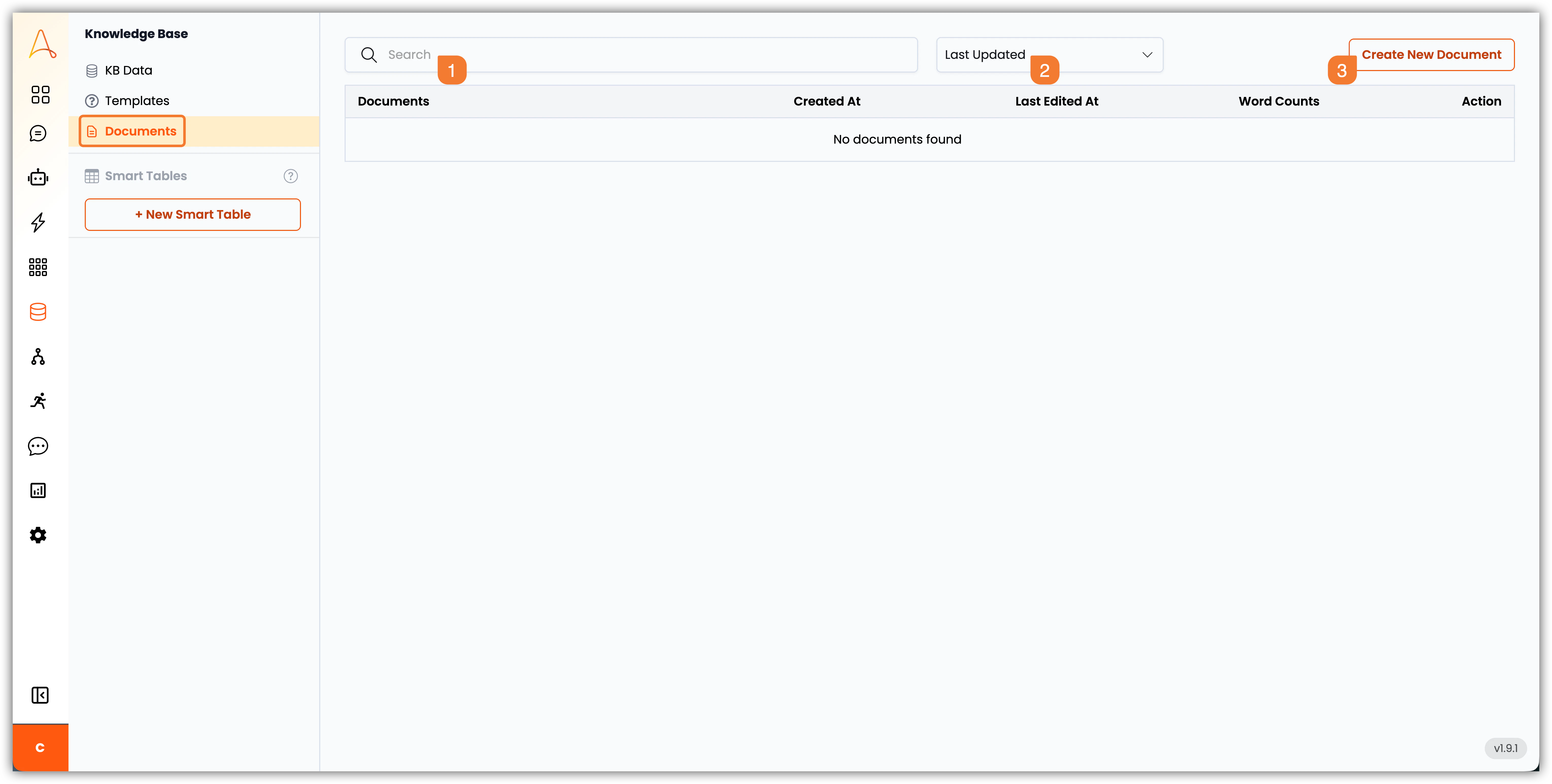 1. **Barre de recherche** : Utilisez la barre de recherche pour trouver rapidement des documents spécifiques.
2. **Filtre** : Utilisez le filtre pour afficher les documents par : `Dernière mise à jour`, `Date de création`, `Titre` ou `Nombre de mots`.
3. **Créer un nouveau document** : Cliquez sur ce bouton pour créer un nouveau document.
## Tableaux intelligents
Les **Tableaux intelligents** sont des tableaux dynamiques et ressemblant à des feuilles de calcul conçus pour stocker, organiser et extraire des données structurées, en particulier à partir de sources non structurées telles que les PDF, DOCX et documents numérisés. Ils sont plus que de simples tableaux ; ce sont des espaces de travail intelligents où vous pouvez télécharger des documents, extraire les données clés à l'aide de l'IA et structurer les données d'une manière qui rend la prise de décision et l'automatisation transparentes. Les applications sont infinies !
1. **Barre de recherche** : Utilisez la barre de recherche pour trouver rapidement des documents spécifiques.
2. **Filtre** : Utilisez le filtre pour afficher les documents par : `Dernière mise à jour`, `Date de création`, `Titre` ou `Nombre de mots`.
3. **Créer un nouveau document** : Cliquez sur ce bouton pour créer un nouveau document.
## Tableaux intelligents
Les **Tableaux intelligents** sont des tableaux dynamiques et ressemblant à des feuilles de calcul conçus pour stocker, organiser et extraire des données structurées, en particulier à partir de sources non structurées telles que les PDF, DOCX et documents numérisés. Ils sont plus que de simples tableaux ; ce sont des espaces de travail intelligents où vous pouvez télécharger des documents, extraire les données clés à l'aide de l'IA et structurer les données d'une manière qui rend la prise de décision et l'automatisation transparentes. Les applications sont infinies !
Explorons les fonctionnalités clés de la section Tableaux intelligents :
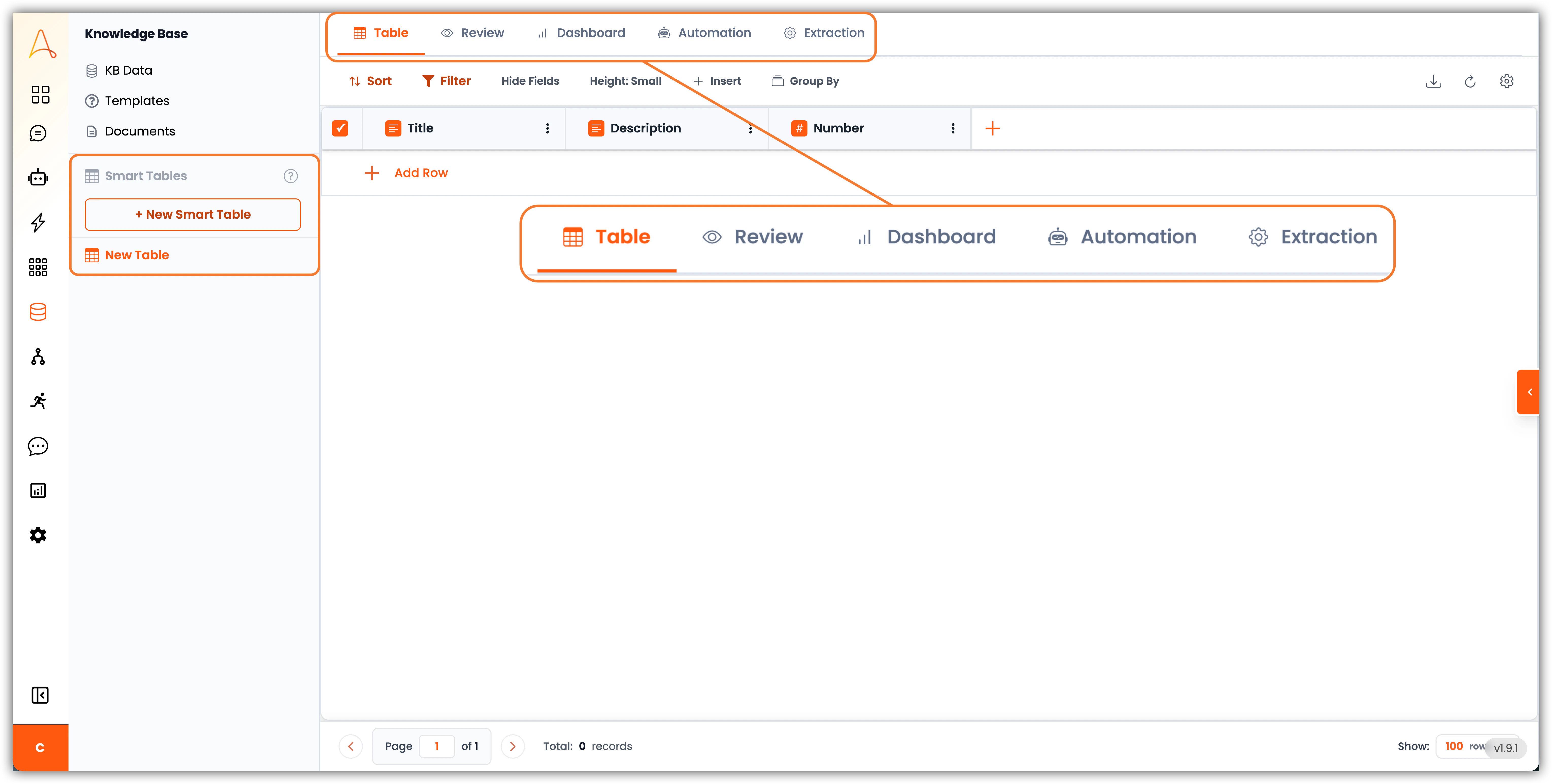 1. **Navigation** – Sur le côté gauche, nous avons le bouton **+ Nouveau Tableau intelligent** et la liste des Tableaux intelligents que vous avez créés auparavant. Si vous survolez le bouton, il affichera quelques options pour créer un nouveau tableau :
* **Créer un tableau vide**
* **Importer à partir d'un fichier**
* **Créer à partir d'un modèle**
2. **Onglet Tableau** – Ceci est la page principale où vous pouvez voir toutes les données de votre Tableau intelligent avec une vue ressemblant à une feuille de calcul. Ici, vous pouvez voir toutes vos lignes et vos champs clairement ; idéal pour organiser et éditer les données directement.
3. **Onglet Révision** – Cette vue est conçue pour le processus humain dans la boucle, qui est utile lors de la validation ou de la modération des données extraites avant approbation.
4. **Tableau de bord** – Ici, vous pouvez créer un tableau de bord pour visualiser vos données avec des graphiques, des comptages et des statistiques.
5. **Automatisation** – Dans les Tableaux intelligents, vous pouvez créer des colonnes avec une tâche pour calculer une valeur ou même utiliser un agent IA ou un LLM pour effectuer une évaluation ou trouver des informations basées sur les informations de votre tableau. L'onglet Automations est où vous configurez l'ordre d'exécution des colonnes et le suivi de l'historique pour les calculs automatisés de ces colonnes.
6. **Extraction** – Cet onglet est la mine d'or pour l'extraction de documents pilotée par l'IA. Ici, vous pouvez configurer les données à extraire, les mapper à vos colonnes de tableau et configurer la façon dont les données sont extraites.
[En savoir plus sur les Tableaux intelligents](/knowledge-base/smart-tables)
## Interface de visualisation des documents
Lorsque vous cliquez sur un document dans la Base de connaissances, l'interface de visualisation du document s'ouvre. Ici, vous pouvez lire et gérer les métadonnées du document et les informations connexes. L'interface est divisée en deux sections principales : la zone de contenu du document et la barre latérale des métadonnées.
1. **Navigation** – Sur le côté gauche, nous avons le bouton **+ Nouveau Tableau intelligent** et la liste des Tableaux intelligents que vous avez créés auparavant. Si vous survolez le bouton, il affichera quelques options pour créer un nouveau tableau :
* **Créer un tableau vide**
* **Importer à partir d'un fichier**
* **Créer à partir d'un modèle**
2. **Onglet Tableau** – Ceci est la page principale où vous pouvez voir toutes les données de votre Tableau intelligent avec une vue ressemblant à une feuille de calcul. Ici, vous pouvez voir toutes vos lignes et vos champs clairement ; idéal pour organiser et éditer les données directement.
3. **Onglet Révision** – Cette vue est conçue pour le processus humain dans la boucle, qui est utile lors de la validation ou de la modération des données extraites avant approbation.
4. **Tableau de bord** – Ici, vous pouvez créer un tableau de bord pour visualiser vos données avec des graphiques, des comptages et des statistiques.
5. **Automatisation** – Dans les Tableaux intelligents, vous pouvez créer des colonnes avec une tâche pour calculer une valeur ou même utiliser un agent IA ou un LLM pour effectuer une évaluation ou trouver des informations basées sur les informations de votre tableau. L'onglet Automations est où vous configurez l'ordre d'exécution des colonnes et le suivi de l'historique pour les calculs automatisés de ces colonnes.
6. **Extraction** – Cet onglet est la mine d'or pour l'extraction de documents pilotée par l'IA. Ici, vous pouvez configurer les données à extraire, les mapper à vos colonnes de tableau et configurer la façon dont les données sont extraites.
[En savoir plus sur les Tableaux intelligents](/knowledge-base/smart-tables)
## Interface de visualisation des documents
Lorsque vous cliquez sur un document dans la Base de connaissances, l'interface de visualisation du document s'ouvre. Ici, vous pouvez lire et gérer les métadonnées du document et les informations connexes. L'interface est divisée en deux sections principales : la zone de contenu du document et la barre latérale des métadonnées.
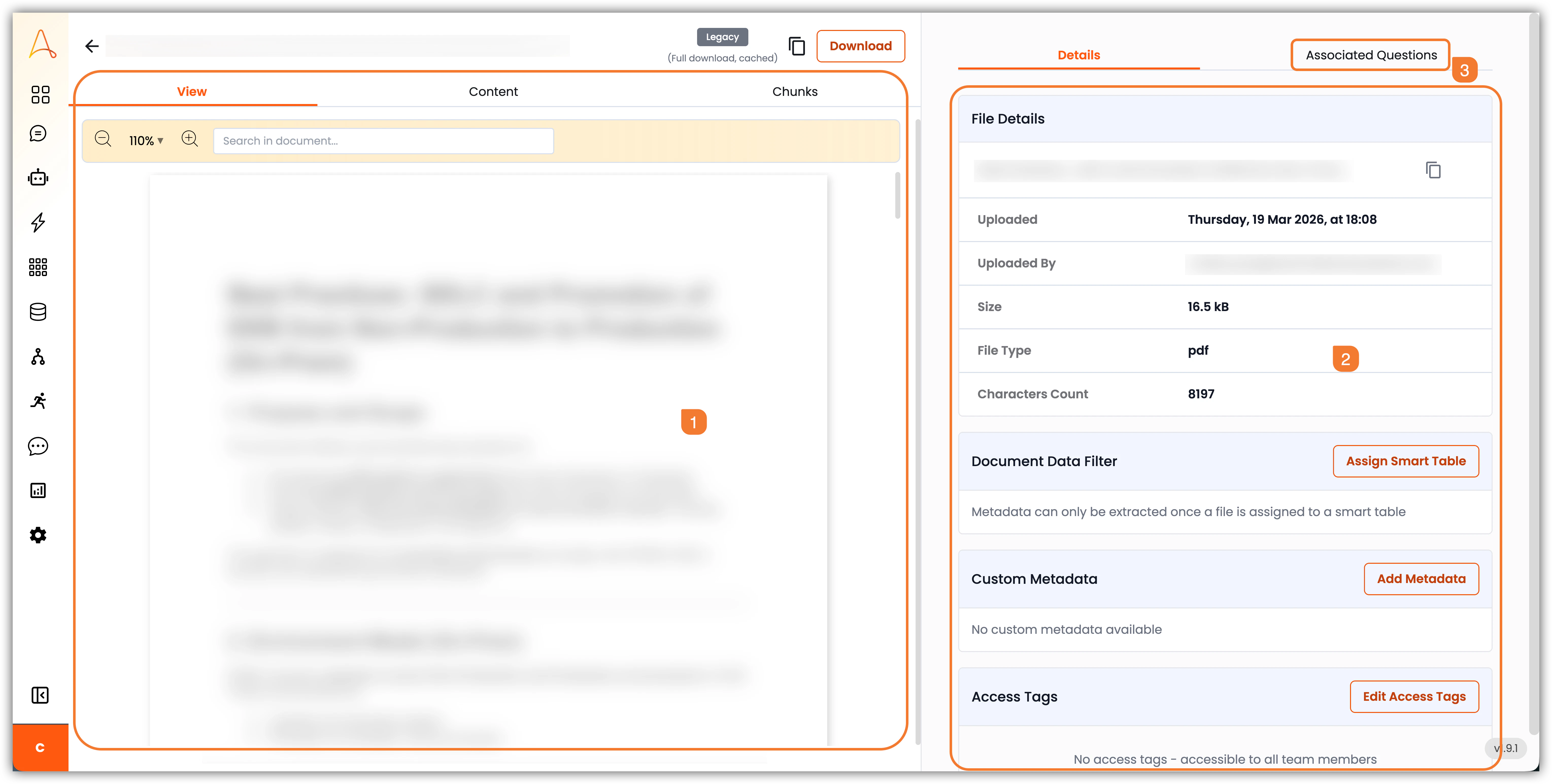 1. **Zone de contenu du document** : C'est là que le contenu principal du document s'affiche. En haut de l'écran, il y a des boutons pour copier le nom du fichier ou télécharger le fichier. **Il y a trois onglets dans cette zone** :
1. **Zone de contenu du document** : C'est là que le contenu principal du document s'affiche. En haut de l'écran, il y a des boutons pour copier le nom du fichier ou télécharger le fichier. **Il y a trois onglets dans cette zone** :
**a**. **Affichage** : Affiche le contenu du fichier tel que téléchargé.
**b**. **Contenu** : Affiche le contenu textuel extrait du fichier. C'est le contenu que l'agent IA utilisera pour la récupération et la réponse aux questions.
**c**. **Fragments** : Affiche les fragments individuels de texte créés en fonction de la stratégie de fragmentation configurée dans les paramètres de la Base de connaissances. Chaque fragment est un segment plus petit du document qui peut être récupéré indépendamment par l'agent IA.
2. **Barre latérale Détails** : Cette barre latérale fournit des informations et des options supplémentaires, notamment :
**d**. **Détails du fichier** : Affiche les informations relatives au fichier, telles que le nom du fichier, la date de téléchargement, l'utilisateur qui a téléchargé, la taille du fichier, le type de fichier et le nombre de caractères.
**e**. **Filtre de données du document** : Vous permet d'assigner un Tableau intelligent au document pour l'extraction de données structurées, en fonction du schéma du Tableau intelligent.
**f**. **Métadonnées personnalisées** : Vous permet d'ajouter des champs de métadonnées personnalisés au document pour une meilleure catégorisation et récupération basée sur l'IA, tels que : Nom de l'auteur, Version, Pages, Résolution, Dimensions, Créateur de contenu, Mots-clés ou toute autre information pertinente.
**g**. **Balises d'accès** : Vous permet d'ajouter des balises d'accès au document pour contrôler qui peut afficher ou interagir avec le document. Vous pouvez créer de nouvelles balises à partir du **Tableau de bord du Super Admin**.
3. **Questions associées** : L'onglet Questions associées vous permet d'ajouter des questions couramment posées connexes qui peuvent être répondues par le contenu du document. Cela aide à améliorer la capacité de l'agent IA à fournir des réponses précises et pertinentes en fonction du contenu du document.
## Dépannage
Cette section couvre les problèmes courants que les utilisateurs rencontrent avec la Base de connaissances et les étapes de diagnostic de niveau 1 (L1) pour les identifier et les résoudre.
### La base de connaissances ne se met pas à jour
**Symptômes :**
* Les nouveaux documents téléchargés n'apparaissent pas dans les résultats de recherche
* Les modifications des documents existants ne sont pas reflétées dans les réponses de l'IA
* Les données du connecteur ne se synchronisent pas
**Étapes de diagnostic L1 :**
1. **Vérifier l'état de la synchronisation**
* Accédez à **Paramètres** > **Synchronisation et planification**
* Vérifiez si la synchronisation automatique est activée et vérifiez l'horodatage de la dernière synchronisation
* Recherchez les messages d'erreur ou les tentatives de synchronisation échouées
2. **Vérifier le traitement des documents**
* Ouvrez le document dans la Base de connaissances
* Vérifiez l'onglet **Contenu** pour vous assurer que le texte a été extrait correctement
* Passez en revue l'onglet **Fragments** pour vérifier que la fragmentation a été complétée
* Recherchez les erreurs de traitement dans les métadonnées du document
3. **Vérifier la cohérence du modèle d'intégration**
* Accédez à **Paramètres** > **Onglet Paramètres**
* Vérifiez que le modèle d'intégration utilisé pour l'indexation correspond à celui utilisé pour les requêtes
* Assurez-vous que le modèle d'intégration n'a pas été modifié après l'indexation des documents
4. **Synchronisation manuelle**
* Cliquez avec le bouton droit sur le document ou le dossier
* Sélectionnez **Synchroniser** pour déclencher manuellement le retraitement
* Attendez la fin de la synchronisation et vérifiez si le problème est résolu
5. **Examiner l'état du connecteur**
* Si vous utilisez des connecteurs (Google Drive, SharePoint, etc.), vérifiez l'état du connecteur dans **Paramètres** > **Connecteurs**
* Vérifiez que l'authentification est toujours valide
* Vérifiez les erreurs de connexion ou les avertissements relatifs aux limites de débit
### Désajustement de recherche
**Symptômes :**
* Les requêtes de recherche ne renvoient pas de documents pertinents
* L'agent IA ne trouve pas les informations qui existent dans la Base de connaissances
* Résultats de recherche incorrects ou non pertinents
**Étapes de diagnostic L1 :**
1. **Vérifier le contenu du document**
* Ouvrez le document et vérifiez l'onglet **Contenu**
* Assurez-vous que le contenu du texte est exact et complet
* Vérifiez que le document a été traité correctement (pas d'erreurs d'extraction)
2. **Vérifier la configuration de la fragmentation**
* Examinez **Paramètres** > **Paramètres** > **Stratégie de fragmentation**
* Vérifiez que les paramètres de taille de fragment et de chevauchement sont appropriés pour votre contenu
* Déterminez si la taille du fragment est trop grande (peut manquer des informations spécifiques) ou trop petite (peut perdre le contexte)
3. **Examiner le modèle d'intégration**
* Confirmez que le modèle d'intégration en cours d'utilisation convient à votre type de contenu
* Vérifiez si le modèle prend en charge la langue de vos documents
* Vérifiez la cohérence du modèle d'intégration entre l'indexation et les requêtes
4. **Tester la requête de recherche**
* Essayez différentes formulations de la même requête
* Utilisez les mots-clés qui apparaissent dans le contenu du document
* Vérifiez si la recherche fonctionne mieux avec des phrases exactes plutôt que des mots-clés
5. **Vérifier les métadonnées du document**
* Examinez les métadonnées personnalisées et les balises assignées aux documents
* Assurez-vous que les documents sont correctement catégorisés et balisés
* Vérifiez que les balises d'accès ne restreignent pas la visibilité
6. **Examiner les fragments**
* Ouvrez l'onglet **Fragments** du document
* Vérifiez que les fragments contiennent les informations attendues
* Vérifiez si les informations pertinentes sont divisées entre plusieurs fragments
### Données non visibles
**Symptômes :**
* Les documents n'apparaissent pas dans la liste de la Base de connaissances
* Les fichiers téléchargés ne s'affichent pas
* Les données du connecteur ne sont pas visibles après la synchronisation
**Étapes de diagnostic L1 :**
1. **Vérifier les filtres de fichier**
* Examinez le filtre de type de fichier en haut de la page Données KB
* Assurez-vous que le filtre n'exclut pas votre type de document
* Essayez d'effacer tous les filtres pour voir tous les documents
2. **Vérifier l'état du téléchargement**
* Vérifiez si le téléchargement s'est terminé avec succès
* Recherchez les messages d'erreur lors du téléchargement
* Vérifiez que la taille du fichier et le format sont pris en charge
3. **Examiner la structure des dossiers**
* Vérifiez si les documents se trouvent dans un sous-dossier
* Naviguez dans les dossiers pour localiser le document
* Utilisez la barre de recherche pour trouver le document par son nom
4. **Vérifier les autorisations d'accès**
* Vérifiez que vous avez l'accès pour afficher le document
* Vérifiez que les balises d'accès ne restreignent pas la visibilité
* Assurez-vous que vous êtes connecté avec le bon compte
5. **Examiner l'état du traitement**
* Les documents peuvent encore être en traitement après le téléchargement
* Vérifiez le statut du document dans la liste des fichiers
* Attendez quelques minutes et rafraîchissez si le traitement est en cours
6. **Vérifier la configuration du connecteur**
* Si vous utilisez des connecteurs, vérifiez les paramètres du connecteur
* Vérifiez que les dossiers/fichiers corrects sont sélectionnés pour la synchronisation
* Vérifiez que le calendrier de synchronisation est configuré correctement
### Conseils de dépannage supplémentaires
* **Effacer le cache du navigateur** : Parfois, les problèmes d'interface utilisateur peuvent être résolus en effaçant le cache du navigateur
* **Vérifier la console du navigateur** : Ouvrez les outils de développement du navigateur (F12) et vérifiez les erreurs JavaScript
* **Vérifier la connexion réseau** : Assurez-vous d'une connexion Internet stable pour les opérations de synchronisation
* **Examiner les journaux du système** : Vérifiez les journaux du système EKB pour les erreurs du serveur (nécessite un accès administrateur)
* **Contacter le support** : Si les problèmes persistent après les diagnostics L1, contactez [support@automationanywhere.com](mailto:support@automationanywhere.com) avec :
* Description du problème
* Étapes prises pour diagnostiquer
* Captures d'écran des messages d'erreur
* Noms des documents/fichiers affectés